
A Beginner’s Guide to Interconnects in AI Datacenters
Understanding performance and trade-offs shaping interconnect choices in AI datacenters.

Welcome to a 🔒 subscriber-only deep-dive edition 🔒 of my weekly newsletter. Each week, I help investors, professionals and students stay up-to-date on complex topics, and navigate the semiconductor industry.
If you’re new, start here. As a paid subscriber, you will get additional in-depth content. We also have student discounts and lower pricing for purchasing power parity (see discounts). See here for all the benefits of upgrading your subscription tier!
Interconnects in datacenters are equally if not more important than compute and memory.
Considering that a single rack has 2 kilometers of copper, and there are hundreds of racks in a datacenter, the sheer scale of AI datacenter deployments makes interconnects an interesting business opportunity.
Interconnects range from a few millimeters in on-die connections to high speed optical links that run hundreds of kilometers and hook entire datacenters together. This makes the choice of interconnect a critical factor in the design of datacenters that determines performance, power consumption and total cost of ownership.
In this deep-dive post, we will discuss how interconnects connect various parts of a datacenter, what kinds of interconnects are best for what application, and what the future holds.
We will cover:
Overview of AI datacenter networking: A high level view of what networks constitute a datacenter.
Compute fabric: A detailed look at how GPUs are hooked up in a rack using NVLink as an example.
Backend network: How racks are connected together using ToR switches and leaf-spine-core architectures, how Nvidia uses rail-optimization, and how networking is disaggregated into its own rack.
Frontend, out-of-band, datacenter networks: How racks are connected to the outside world, and for monitoring purposes.
For paid subscribers:
Interconnect distances and speeds: What signaling speeds are used at the GPU, intra- and inter-rack levels, and how reach plays a role.
Copper versus Optical: Where to use what, and why.
Speed and reach tradeoff: Understanding the key tradeoffs required to choose the correct interconnect technology at any point in the datacenter.
Copper interconnect technologies: A look at DAC, ACC and AEC copper cables, what technologies in them enables higher reach, pros and cons regarding power, cost and reach, and where they are used in datacenters.
Where is all this going? A short discussion on why copper is not dead, and where optics might play a role going forward.
Read time: 13-15 mins
Top Level View of an AI Datacenter Network
To understand interconnect requirements, let us start at the level of the AI datacenter and understand how the network is constructed.
AI datacenters have multiple data halls in which there are many IT racks containing compute and networking hardware. Each IT rack has multiple compute servers and network switches which are all connected together using intra-rack networks. Each compute server also has multiple CPUs/GPUs, which are also connected together. The racks themselves are connected together using inter-rack networks and ultimately, datacenters are connected to the outside world including other datacenters.
The interconnect requirements for each of these networks is different. Depending on their function in a datacenter, there are five types of networks within the data center: compute fabric, backend, frontend, out-of-band, and datacenter interconnect. We will discuss each one briefly and then present the interconnect technologies available to implement network connections.

I would also recommend reading Austin Lyon’s two part introduction to GPU networking in datacenters for a gentle introduction to this topic because what follows will be more detailed.
Compute fabric
This network connects GPUs, CPUs and memory within a compute server. They can also connect different compute nodes within a rack in what is called scale-up networking. Let us look at Nvidia’s DGX GB200 as an example.
A single NVL72 rack has 18 compute trays and 9 switch trays. Every compute tray has 2 GB200 superchips, each of which contains 1 Grace CPU and 2 Blackwell GPUs. Thus, for 18 compute trays, there are 18×4 = 72 GPUs. Also, each GPU has 18 NVLink 5.0 (Nvidia proprietary PHY) links, which means that a total of 72×18 = 1,296 ports are required to hook them all up so that all GPUs are interconnected.
A single switch tray contains two NVLink Switch chips, each with 72 NVLink ports or a total of 72×2 = 144 ports per tray. For 9 switch trays, there are a total of 1,296 switch ports in a rack. The switch port count matches the total number of NVLink connections from the GPU allowing all GPUs act as a single logical unit.
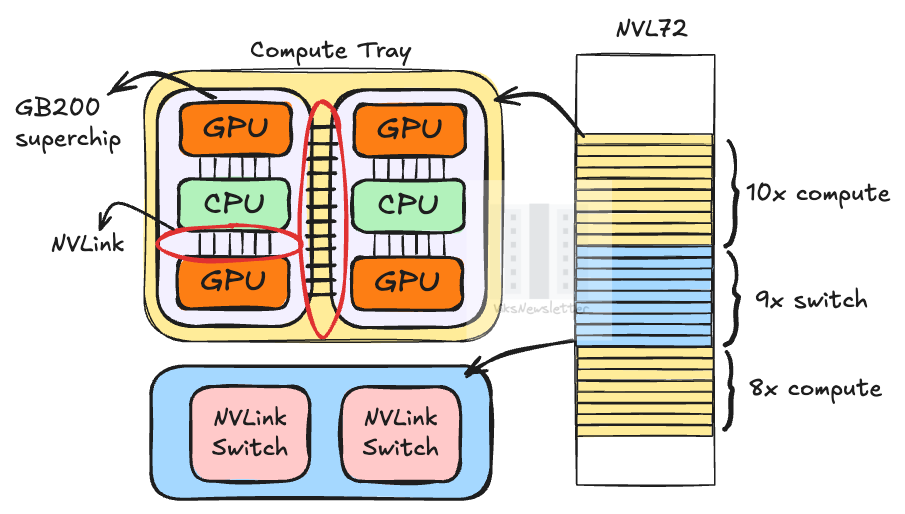
It is important to note that NVLink 5.0 connects 72 GPUs together across three levels that use very different interconnect technologies:
On-chip interconnect between the CPU and two GPUs inside a GB200 superchip. The superchip itself does not have a switch chip to link the two GPUs together. Instead, they are linked to the overall NVLink domain so that networking can be done externally.
Board level interconnect between the two GB200 superchips inside a single compute server. This is still called NVLink C2C (chip-2-chip) even if the interconnection is made on a PCB. In earlier generations, the board also included an NVSwitch chip for networking. But in GB200, it has been moved out of the board and into the network tray.
Rack level interconnect between the 18 compute trays and 9 switch trays using copper cables. Nvidia’s implementation at this level is still called NVLink. The picture below shows the NVLink Spine that houses a high density of copper cables to connect compute and networking servers together in a rack.

Alternatives to NVLink such as Infinity Fabric (AMD) and Universal Accelerator Link (UALink, an open-standard) exist for linking GPUs into a single domain which we won’t get into here.
Backend Network
While the compute fabric provides intra-rack networking, the backend network provides inter-rack connectivity to expand the AI cluster with multiple racks - also called the scale-out network. We just calculated that all 1,296 network ports in the switch trays are fully connected to GPUs. How then does the rack communicate with other racks?
Leaf, Spine and Core Switches
This requires a separate network switch in a rack called the Top-of-Rack (ToR) switch, sometimes also called a leaf switch when referring to the network architecture. Recent rack architectures have moved the ToR switch out of the rack, but its useful to understand it this way for legacy reasons.
Nvidia’s latest solution for inter-rack networking is the Quantum-X800 switch that supports their proprietary InfiniBand standard. The Quantum-X800 has a total of 144 ports that can be used to make connections between GPUs in the rack and other leaf switches in neighboring racks in a pod.

In addition to the NVLink ports in every compute tray, there is also a network interface that allows it to connect to the Quantum-X800 switch. This is typically implemented with four ConnectX-7/8 network interface cards (NICs), one per GPU in the compute tray. For 18 compute trays, there is a total of 18×4 = 72 NICs that will connect every GPU to leaf switch. A part of the remaining 72 ports in the leaf switch will be used to connect to other racks.
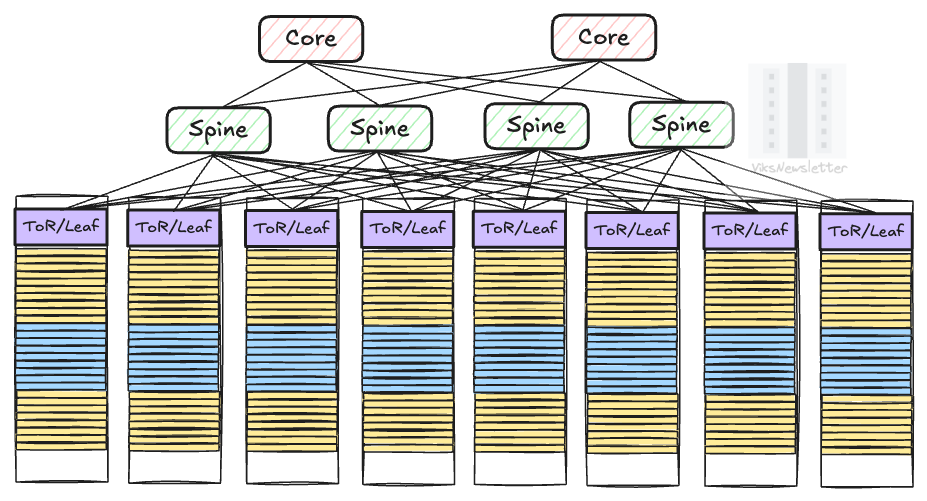
If a leaf switch with a smaller number of ports is used, like the earlier generation Quantum-2 switch with 64 ports, then an additional layer of switches needs to be added on top of the leaf switches to make the required connections across racks. These are called spine switches, and they introduce additional latency when making GPU hops across racks. If the number of ports per switch is even lower, or the number of racks is larger, a third layer of network switches called the core layer may be used at the cost of even higher latency between GPU hops.
Rail-Optimized Configuration
There is a tendency to imagine that all the NICs from a single rack will be connected to the same ToR/leaf switch in the rack. Nvidia instead uses a rail-optimized architecture that connects GPUs from a single rack to different leaf switches in other racks. The advantage of doing this is that a hop to a spine switch can be avoided when distributing workloads across GPUs in different racks. The downside is that a longer cable is needed to connect to leaf switches on a different rack; a more sophisticated cable that supports high data rates over long distances is required.
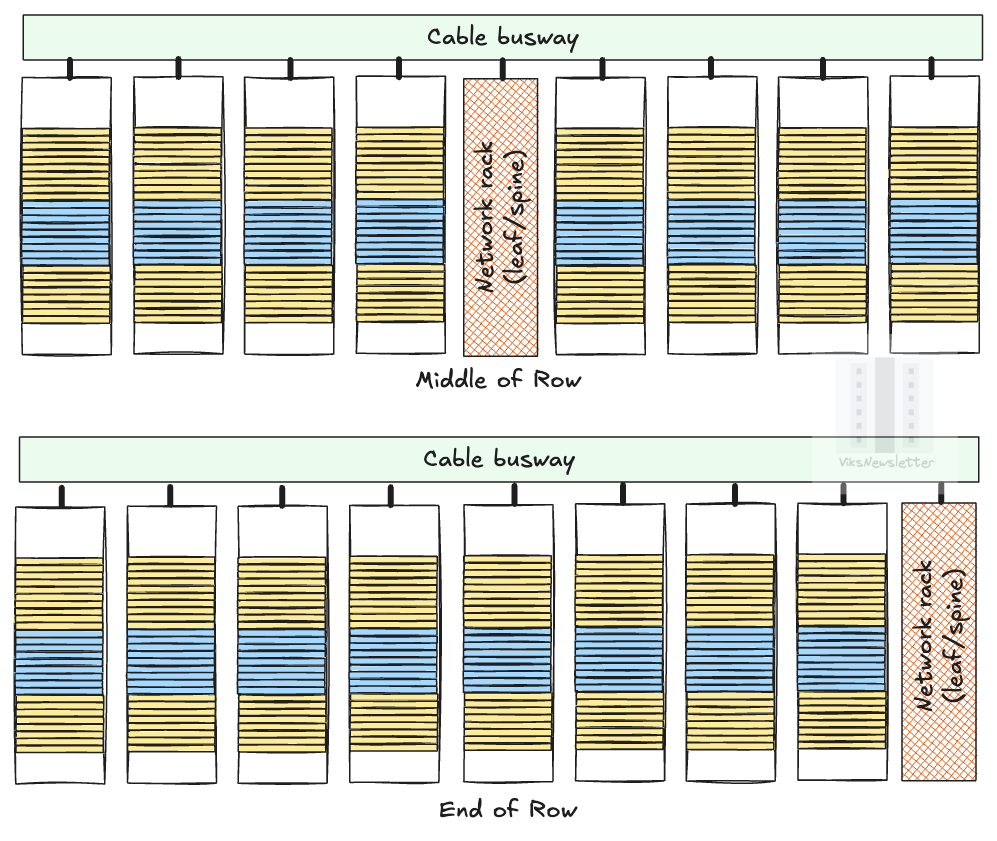
Networking Racks
Another approach to hook up racks together is to put all the switch gear into its own rack which may be placed in the middle of the racks in a pod as shown below (Middle-of-Row) or at the end of the row (End-of-Row). This is the approach Nvidia is taking in its DGX Superpod.
The advantages of isolating networking gear are many: large leaf/spine switches such as the Quantum-X800 benefit from dedicated cooling systems, the cable clutter from racks is improved after centralization, and much easier to service if something goes wrong in the network. The major downside is that all the connections from the compute racks to the leaf/spine will likely require optical fiber and transceivers due to the long length of cable runs needed. This will drive up the cost compared to using just copper cables.
Frontend, Out-of-Band and Datacenter Networks
The frontend network is just a regular ethernet connection (as opposed to InfiniBand in the backend) that interfaces the racks to storage bays, load balancers, and external services that do things like load model weights, and move the computation results to storage. In Nvidia GB200 racks, there are two Bluefield Data Processing Units (DPUs) per compute tray that provide connectivity to the frontend network.
Frontend network bandwidths are usually much slower than backend. High throughput connections that are needed for training/inference are handled by the backend network; the frontend only provides application level services.
Out-of-band networks in the datacenter are present to monitor the health of the hardware in the racks. Things like temperature, power consumption, fan speeds, and operating system upgrades are all handled through this network.
Finally, the Data Center Interconnect (DCI) network connects the data center to the outside world or to other datacenters for multi-datacenter training runs. Due to the high bandwidth and reach required, these are exclusively optical fiber interconnects.
After the paywall:
Interconnect distances and speeds: What signaling speeds are used at the GPU, intra- and inter-rack levels, and how reach plays a role.
Copper versus Optical: Where to use what, and why.
Speed and reach tradeoff: Understanding the key tradeoffs required to choose the correct interconnect technology at any point in the datacenter.
Copper interconnect technologies: A look at DAC, ACC and AEC copper cables, what technologies in them enables higher reach, pros and cons regarding power, cost and reach, and where they are used in datacenters.
Where is all this going? A short discussion on why copper is not dead, and where optics might play a role going forward.