
Context Memory Storage Systems, Disruption of Agentic AI Tokenomics, and Memory Pooling Flash vs DRAM
How a new storage tier unlocks long context inference for agents, and dramatically drops cache storage costs. Storage system specifics, potential winners, and risks.

Special thanks to Val Bercovici, Chief AI Officer, WEKA (LinkedIn, X) for reading draft versions of this post and providing detailed feedback. The quality of the article is much higher as a result. All mistakes are mine.
Last week at CES 2026, Nvidia announced the Inference Context Memory Storage (ICMS) platform that allows the use of NAND SSDs to dramatically expand Key-Value cache (KV$) storage. The technology is not fundamentally new; Weka, VAST Data and Dell already have their solutions for handling KV$ in external storage systems. This technology has an outsized impact on agentic AI systems and the resulting inference tokenomics. This discussion is largely missing from industry commentary.
According to Manus AI who were recently acquired by Meta for $2B, “KV cache hit-rate” is the most important metric for agentic AI systems because a KV$ miss costs ten times more than a cache hit, especially when AI agents generate 100x more tokens than human users.
In this post, we will explore the importance of this new storage tier in agentic AI, how it solves the cache-hit problem, who captures the resulting value, and potential bear cases for disaggregated context storage.
This report covers the following in-depth:
Why context storage matters now and the basics of cache tokenomics (free section)
KV Cache offloading to different memory tiers, including benefits of Vera Rubin architecture.
Implementation of context memory systems, possible supplier of ICMS systems to Nvidia, and NVMe storage architecture including the number, capacity, and bandwidth of SSDs.
Context memory storage impact on agentic AI tokenomics; what we can expect going forward with concrete examples from WEKA.
Potential hardware winners in the era of context storage.
Risks to the adoption of SSD-based context storage, and where DRAM pooling fits in.
If you’re not a paid subscriber, you can buy just this report in EPUB and PDF formats using the button below.
Why Context Storage Matters Now
“Context” refers to the set of tokens held in working memory by an LLM. Large context is useful for processing larger blocks of inputs to an LLM, like multiple books at once, large codebases, or large videos. Due to the way Attention is calculated in an LLM, context is closely linked to the KV$ which grows linearly with context length. If it grows too large, it must either be moved to a higher capacity (but slower) storage device, or somehow compacted in place. If the KV$ retrieval from storage is too slow, Time To First Token (TTFT) is impacted greatly, and it is faster to just recompute the KV matrices again at the cost of higher GPU utilization. If KV$ is compressed, it loses accuracy and adds error. In effect, KV$ handling affects overall token throughput and ultimately, inference tokenomics.
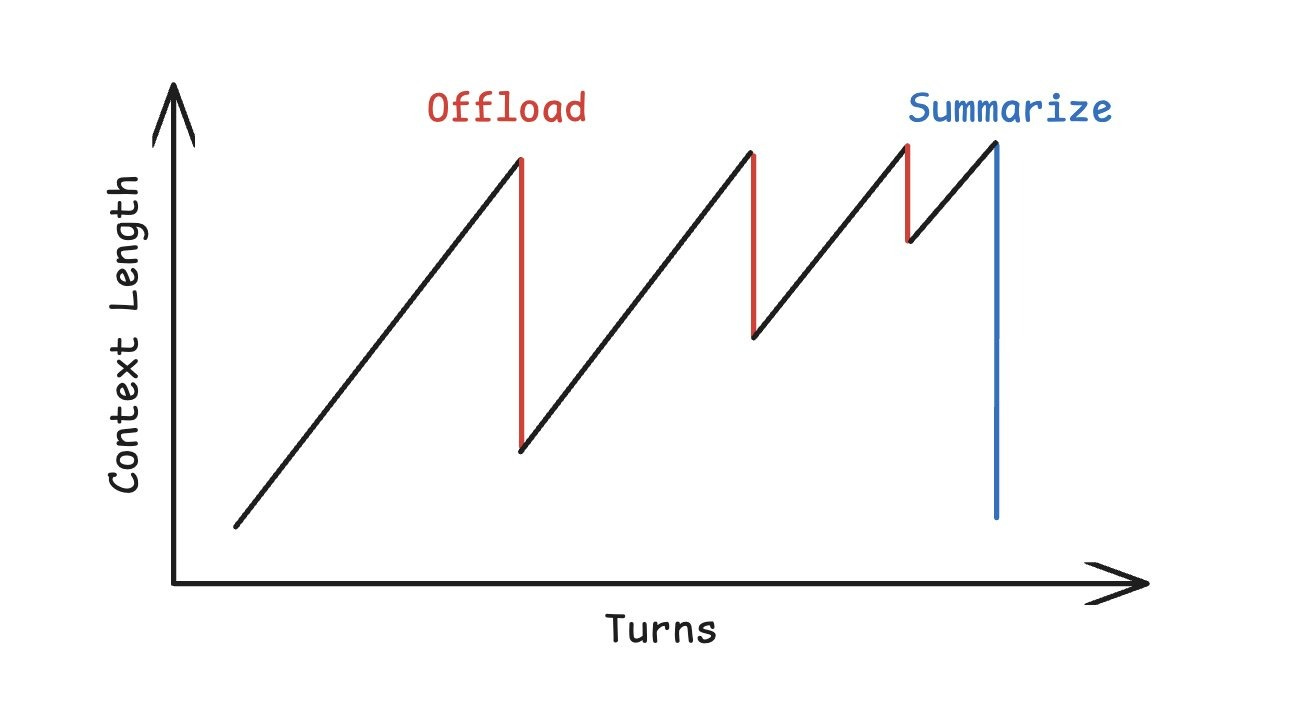
As a result, context memory is a scarce resource that must be carefully engineered and is as important as GPU utilization rates in the era of agentic AI inference.
Cache Tokenomics
Let’s take the example of Claude’s token cost structure to understand the importance of KV$ for workloads, and how the economics works. The token arbitrage reflected in the pricing structure below is important to understand.
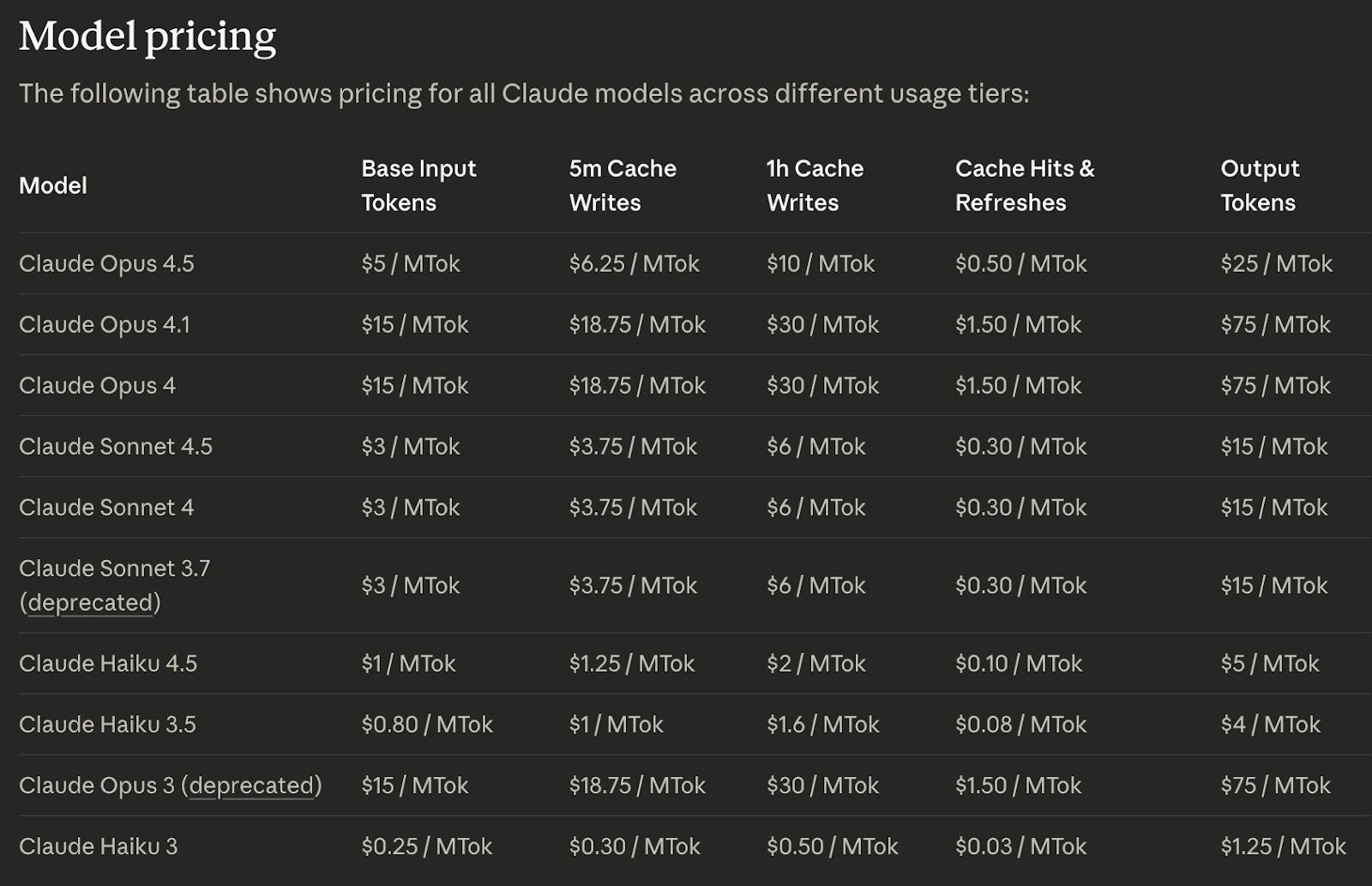
The first thing to note is that cache hits cost $0.5 per million tokens ($0.5/Mtok), while input and output tokens cost $5/Mtok and $25/Mtok, respectively, for Anthropic’s frontier model - Opus 4.5, for example. In order to guarantee cache hits and reduce overall cost, it is important to write critical context to the cache and have it available for a given length of time called Time-To-Life (TTL). It costs $6.25/MTok to write to cache and keep it there for 5 minutes. A TTL of 1 hour costs $10/Mtok. Depending on the model, there could be higher pricing for long contexts as shown for Sonnet 4.5 below.
During the evaluation of Attention in an LLM, if the KV$ is readily available, then a lower cost is incurred during the process of inference. If there is a cache miss, the KV$ needs to be recomputed which incurs significantly higher costs at input token levels. This also requires additional GPU allocation which often results in overprovisioning and lower GPU utilization rates overall. Essentially, the 10x cost differential when there is a cache hit versus miss is a major cost driver for inference economics.
The decision of what to write to cache and how long to keep it there depends on how the token context is engineered, especially for agentic AI systems which generate a lot of tokens during tool use and processing of results. Most importantly, the inputs and outputs of each successive tool use needs to be kept in context for agents to successfully complete long context actions which requires an extensive rethinking of how to structure context. Manus describes this in-depth in their blog post.
KV$ Offloading And Memory Tiers
The cost structure of context management in cache has its roots in how it is implemented in hardware.