
GTC 2026 Preview | Implications of Nvidia's SRAM-Decode Hardware on the Inference Market
The case for dedicated decode hardware and what it means for AMD, HBM, and the SRAM startup market.

A recent Wall Street Journal article stirred excitement about NVIDIA’s upcoming GTC 2026 announcements:
The company is designing a new system for “inference” computing, a form of processing that allows AI models to respond to queries, according to people familiar with the plans. The new platform, set to be revealed at Nvidia’s GTC developer conference next month, will incorporate a chip designed by startup Groq.
The announcement is even more anticipated because Jensen compared Groq to Mellanox in the last earnings call, implying that just as Mellanox made Nvidia a networking company in 2020, Groq will transform Nvidia into an inference infrastructure company. Since Nvidia acquired Groq for an eye-watering $20B on Christmas Eve last year, the industry has questioned why Nvidia would choose an SRAM-based architecture with a notoriously challenging compiler especially when many believed Groq’s approach to be sub-optimal. With the rise of agentic AI, model providers like OpenAI have complained that existing systems are too slow. The acquisition of Groq is Nvidia’s answer to inference speed.
Here, we will explore how inference is actually two distinct hardware problems: prefill and decode. Prefill was addressed by the Nvidia CPX chip announcement last year. The upcoming Nvidia system will tackle the latter: specialized decode hardware, dubbed by some as Nvidia LPX.
After the paywall, we will discuss what might be announced at GTC 2026, mid-plane PCB rumors for inference accelerators, what it means for HBM, list of inference startups ripe for acquisition, what AMD needs to do immediately, and Groq’s achilles heel that SRAM-solutions must beat.
If you don’t have a paid subscription, you can purchase just this article in epub and pdf formats using the button below. Check out all the reports available in this link.
Different Hardware for Training vs Inference
The AI age has focused on training first, which requires lots of matrix multiplications and high-bandwidth memory (HBM) to store, update, and backpropagate weights. Using the same hardware for inference is suboptimal because inference has different bottlenecks. Disaggregated inference today revolves around three phases, each requiring different hardware and software: prefill, decode, and orchestration. Chiplog has a nice historical piece on how it came about.
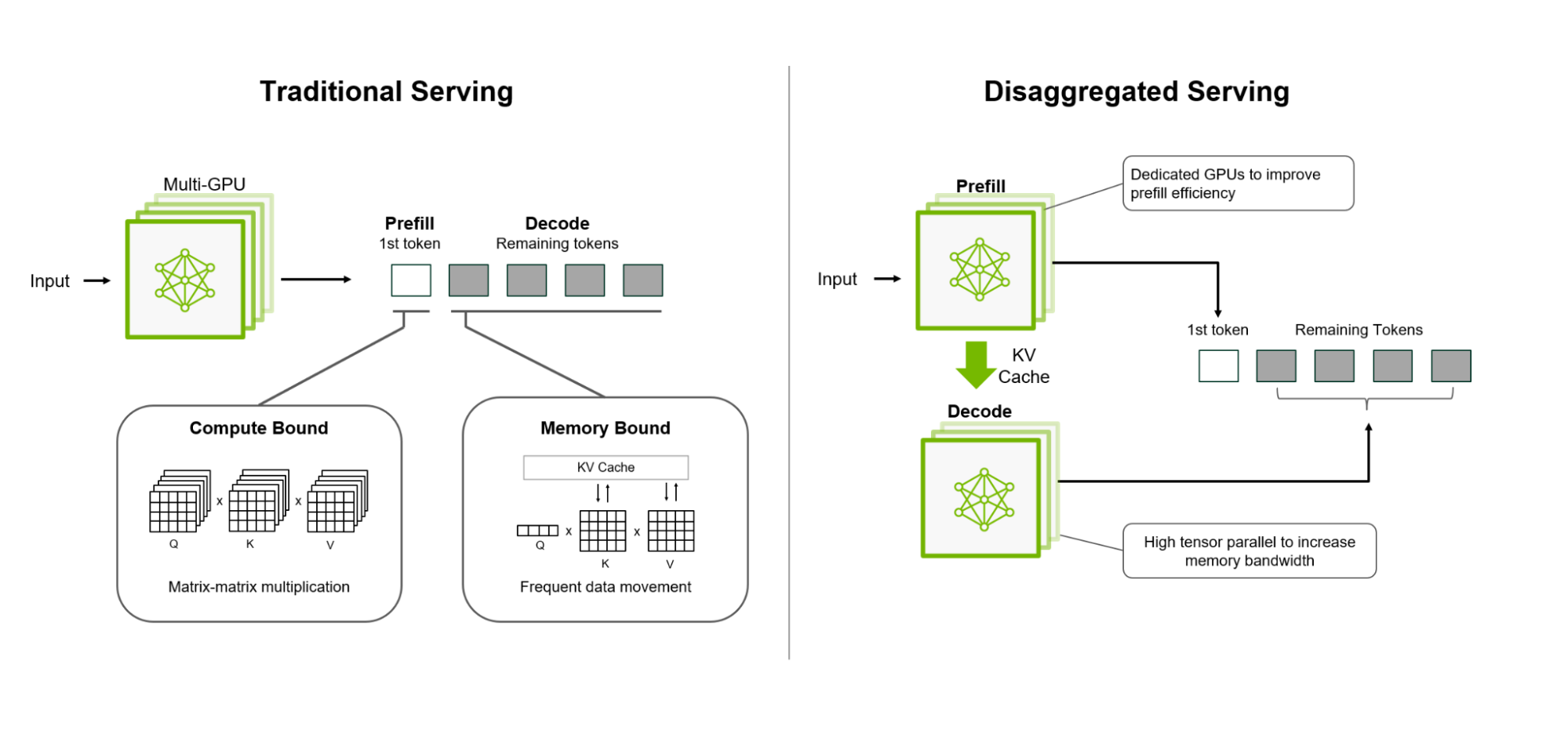
Prefill processes all input tokens simultaneously. Weights are loaded once and multiplied against the entire input sequence in a batch matrix-multiply to create the key-value (KV) cache. This is compute-bound, not memory-bound. Nvidia’s Rubin CPX targets only prefill and uses GDDR7 instead of HBM because memory bandwidth is not the bottleneck.
Decode generates tokens sequentially because of the autoregressive nature of transformers; each token depends on all previous tokens. Since model weights are read from memory for every single token generated, this phase is bottlenecked by memory bandwidth and not compute. GPUs with HBM do not make the best decoding engines because SRAM bandwidth is an order of magnitude higher but with a capacity tradeoff. We have discussed the SRAM-HBM tradeoffs extensively before. Currently, Nvidia’s decode solution is HBM-based and the acquisition of Groq and its IP eliminates the memory bandwidth issue.
Orchestration ties it all together. Nvidia’s Dynamo handles KV-cache movement between prefill and decode, and manages KV-cache evictions to context storage when it outgrows its current tier. In the agentic AI era, the CPU plays an increasingly important role by controlling inputs to prefill, processing outputs from decode, and managing all the software API calls via the Dynamo NIXL library that handles asynchronous communication between compute blocks.
Why LPUs Work for Decode
Groq’s LPU uses SRAM and a Very Large Instruction Word (VLIW) architecture where the hardware makes no runtime decisions, which makes it fast and deterministic to the last clock cycle. The real technological moat lies in orchestrating everything correctly with a cutting edge compiler.
The eight chips in a GroqNode are connected in an all-to-all fashion using short wires whose exact delay is well understood. Then each clock cycle, the chip executes one very wide preconceived instruction that simultaneously controls every functional unit on the chip, for example: “On this cycle, unit A performs this multiplication, unit B moves this data from SRAM bank 3 to bank 7, the network port sends this packet to chip 14.”
Such an operation is well suited to perform the fundamentally simple, sequential task of generating output tokens. In contrast, a general purpose GPU has to make thousands of runtime decisions like when to get data from memory, how to schedule threads, how data is routed between cores, and when operations complete. The flexibility is great but largely overkill, and arguably even bad, for a fixed decoding task. The fixed operation of an LPU allows the full use of the advertised SRAM bandwidth (80 TB/s) without any resource contentions and variability from cache hits/misses.
This is a capability that Nvidia did not have before the acquisition of Groq, and it adds the ability to control the dataflow within a compute block - that in spirit, is similar to systolic arrays in TPUs. The compiler is hard, but it is a solved problem and Nvidia also got the team that solved it. Groq’s chips still run on 14nm technology, and when ported to more recent leading logic nodes, can have much more SRAM per chip.
If you want to go deep into LPU architecture, Confessions of a Code Addict has a great article.
Here is what is after the paywall:
An educated guess of what the GTC 2026 will look like, LPU scaling considerations, and mid-plane PCB rumors.
SRAM-inference impact on HBM and KOPSI correlation
The options for the upcoming land grab in SRAM-based accelerators
What AMD must do yesterday