
How Rack Power Density Is Opening a New Market for Active Copper
As AI racks grow too dense to power and cool, their scale-up networks spread across cabinets, and the short links in between are where active copper finds its market (SMTC, MRVL, CIEN, MTSI, CRDO).

The discussion around interconnects, whether copper or optical, usually revolves around two factors and the trade offs around them: reach and data rate. As data rates rise, reach gets shorter and vice versa. As a result, networking is crudely divided into scale-up and scale-out domains restricting the former to within a single rack, and the latter to between racks.
The rise of power density within a single rack as hyperscalers pack in more GPUs is causing the networking domains to blur. As GPUs per scale-up domain climb, the domain outgrows a single rack and operators split it across racks to keep power density in check. Meta’s Catalina is a prime example where the scale-up domain spreads across racks at lower power density, linked with active copper.
A dense rack like NVIDIA Rubin pulls so much power that many brownfield datacenters (a term used to refer to existing datacenters repurposed for the AI age) cannot host one because the installed racks cannot support the power density. Short of swapping in NVIDIA reference racks as-is, the only way to deploy power-dense hardware is to spread the same GPUs across multiple lower-density racks.
Once power pushes scale-up across racks, passive copper does not have enough reach. But the gap is not wide enough for fully retimed copper with DSPs, which are too power hungry and too high latency, and optics for a few meters is overkill at this networking generation. Active copper fills the gap as a “goldilocks” choice to keep power budgets in check and opens up a new market for AI interconnects.
In this post, we will look at:
A tour of the interconnect technologies inside an AI datacenter, and where passive copper, active copper, DSP cables, and optics each fit.
Why rising rack power is forcing scale-up networks to split across multiple cabinets, with Meta’s Catalina as the worked example.
Which interconnect actually wins the short links between those split racks, and why it turns out to be active copper.
For paid subscribers, a full competitive teardown of the five vendors fighting for ACC: Semtech, Marvell, MACOM, Ciena/Nubis, and the conspicuous one sitting it out.
By reading this post, you agree to the terms and conditions. Also see the full ethics statement.
If you are not a paid subscriber, you can purchase just this article using the button. You can find the whole catalog of articles for purchase at this link.
If you would like to engage boutique research services for your project, click below.
How AI Racks Move Data Today
All scale-up networking inside NVIDIA racks has been passive copper. The NVLink spine holds roughly 5,000 copper cables. Passive copper, or direct attach copper (DAC), works because its reach inside a single rack covers the generation it sits on. The speeds across three NVIDIA generations:

Hopper, at 100G per lane, gave DAC about 3m of reach which is plenty. Blackwell’s NVLink 5 went to 200G per lane and passive reach fell to about 1.5-2m, but NVIDIA kept the scale-up domain inside the spine by packing all 72 GPUs and the NVSwitch trays into one rack with a copper cable spine, so no link runs far.
Rubin’s NVLink 6 was labeled 400G per lane at GTC 2026, though the industry read is 200G bi-directional. Running a transmit+receive pair at once leans hard on echo cancellation and tightens cable performance demands, but DAC for scale-up is alive and well in Rubin. The added BiDi complexity is handled by the SerDes on the switch silicon, not with external redrivers. Rubin Ultra moves to a mid-plane PCB approach, which is still passive copper.
Scale-out is different: connecting a row of racks needs real reach. It has leaned on active electrical cables (AECs), which drove Credo’s purple cable mania a few years back. Marvell and Astera Labs play on the silicon side; Credo is vertically integrated. As speeds climb, scale-out is migrating to optics, pluggable transceivers first, then CPO for lower energy. For linking datacenters across a campus or beyond, optics is already the mainstay.
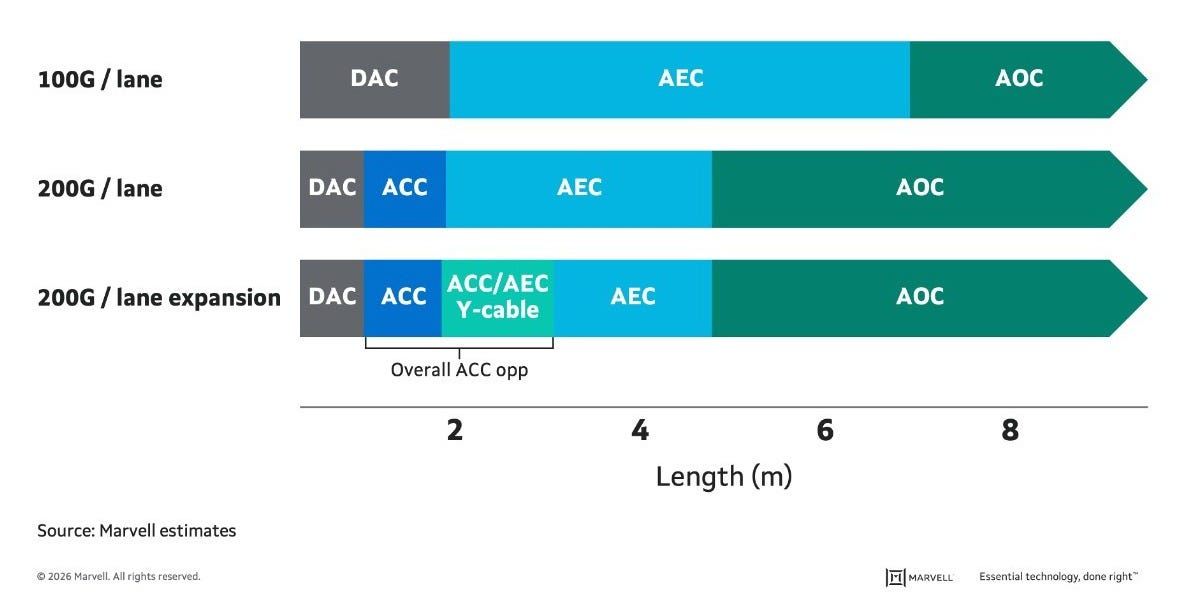
Today, a new space for interconnects is emerging as the scale-up domain spans multiple racks; one whose reach is not high enough for pure optics, but also latency and power sensitive for pluggable optics and fully-retimed copper solutions using DSPs. In the 1.6T generation and possibly beyond, this is the space that Active Copper Cable (ACC) is looking to fill.
Why Meta’s Catalina Spans Two Racks
The cleanest scale-up domain is the one that never leaves the rack because passive copper cables without active silicon is cheap, low-latency, and low-power. This is the sole reason why hyperscalers would all keep scale-up inside one rack if they could.
The fundamental problem is that a frontier scale-up rack like NVIDIA’s Blackwell NVL72 uses more power that traditional racks. Once you cross roughly 100 kW in a single rack, you run out of cooling headroom, busbar capacity, or both, and the only move left is to spread out the GPUs across two racks, and run the scale-up fabric between them.
A single GB200 NVL72 draws around 120-130kW in one rack. If most racks in an existing datacenter top out around 60-70 kW per rack, then NVIDIA offers the same 72-GPU domain repackaged as NVL36x2: two cabinets of 36 GPUs at roughly 67kW each. But what if NVIDIA’s customers have their own racks already?
Meta’s Open Rack v3 High Power Rack (HPR) supports 93.5 kW per-rack, and is not suited to directly deploying a single NVL72 GB200 domain within it. At this point, Meta has to either replace all the racks in its existing datacenter with NVIDIA’s reference architecture, or expand the 72-GPU domain across two racks. This latter is what Meta did with its Catalina racks.

Catalina stretches the 72-GPU NVLink domain across two ORv3 HPR cabinets, roughly 36 GPUs and ~67kW each, so both racks sit comfortably inside the 93.5kW power envelope Meta already knows how to cool and power. The Blackwell silicon is NVIDIA’s, but the rack around it is Meta’s implementation so that the cabinet drops into Meta’s existing data halls instead of forcing a new facility build.
The tradeoff lands on the scale-up traffic which has to jump across the split rack domains. In the picture below, you can see a thick bundle of black cables running between the two racks, tying the GPUs on both sides together through the NVLink switches into a single 72-GPU domain. The backend network within each rack is in-rack scale-up. Holding 72 GPUs non-blocking across that split takes 162 cross-rack links (18 ports/NVswitch × 9 NVswitches/rack). The saving grace is reach because the interconnect just has to go to the neighboring rack scale-up, and not run across an entire row like in scale-out networks.

Which Interconnect Wins Multi-Rack Scale-Up
The cable only has to reach the rack next door, which works out to about 3 meters once you allow for slack. That is a short, fixed reach, and at 200G/lane it is enough to rule most of the options in or out.
Passive copper is the first to go. At 200G/lane a plain DAC runs out of reach well short of 3 meters, so it cannot bridge the gap on its own. At the other extreme, a DSP-based AEC reaches far past 3 meters, but it burns around 20 watts per end and carries the latency of a full retimer, which is overkill when all you have to do is cross to the neighboring rack. Pluggable optics runs into the same wall from the other side. It clears the reach and data rate easily, but tens of watts of transceiver power per end is wasteful on a link that only has to span a few meters.
Co-packaged optics is the interesting one. It is the lowest-power and most future-proof option, and NVIDIA is pushing it for multi-rack scale-up in Rubin Ultra. But it is still unproven at scale and ties you to a handful of vendor ecosystems, so it reads as a next-generation answer rather than something to deploy at 1.6T today. CPO is not the only future bet either, as several players are investigating microLEDs and VCSELs for the same short-reach role, though none of these are in large-scale deployment yet.
That leaves the option built for exactly this gap. Active copper cables add a linear redriver, no DSP, which pushes copper out to 3 meters at 200G/lane for just a couple of watts per end. Most of the reach of an AEC, a fraction of the power, and none of the DSP latency.
After the paywall:
Semtech’s proven design wins, including the marquee platform already running its silicon.
Why Marvell is every bit as strong in ACC as Semtech, for completely different reasons.
Why MACOM has the silicon and a standards seat but no ACC wins to show.
How Ciena bought Nubis for optics and picked up a useful ACC play.
Why the best-known copper-cable company is sitting ACC out.
Finally, a single table to summarize the competitive ACC landscape.