
Cerebras IPO and the Four Bottlenecks in Its Custom-Everything Architecture
A closer look at the wafer-scale architecture, the OpenAI deal, and four design vectors that decide if Cerebras can deploy at scale

Cerebras IPO prices this week, and I’ve gotten a few questions about this: is this a Groq or Nvidia threat, or just another AI infrastructure listing riding the cycle? The IPO is also heavily oversubscribed, to the tune of 20x or more. While Cerebras has higher token throughput than Groq’s LPU, it comes at the cost of design complexity. Everything about Cerebras screams custom – the silicon, packaging, connectors, and power delivery. When every layer is bespoke, it is important to consider the question of scalability, which is an aspect largely missing from the commentary.
What this is not, in my read, is a technology displacement story. Nvidia and Groq LPUs serve the low-latency segment of inference, and can hold its place in the overall inference market. It’s not always zero-sum as the market likes to think it is. Cerebras on the other hand, has massive customer concentration risk in G42, has compute (not hardware) purchase agreements with OpenAI, and lacks the overall software and hardware ecosystem that Nvidia has for its LPUs from Groq.
The investor question is not “does Cerebras affect Nvidia,” but whether the custom-everything architecture can scale revenue past strategic deals with OpenAI without breaking on a single design choice or supplier. We’ll work through four risk vectors in this piece.
If you are not a paid subscriber, you can purchase just this article using the button below. You can find the whole catalog of articles for purchase at this link.
How Wafer-Scale Inference Actually Works
The central idea to Cerebras’ silicon is the Wafer Scale Engine (WSE). While GPUs/TPUs are often diced out of a whole 300mm wafer and then packaged, Cerebras keeps the whole wafer intact – the wafer is the chip and it is 46,225 mm2 in size. The latest iteration WSE-3 has 900k processing cores, 44GB of SRAM per wafer, and a memory bandwidth of 21 PB/s per wafer. For comparison, Groq LPUs “only” have low 100s of TB/s per chip.

To be clear, Cerebras built this enormous wafer-scale chip for training so that the model can remain on the wafer to speed up GPU cluster training by skipping the slow network links between GPUs. But this idea never caught on for training for a couple of reasons:
Memory bandwidth was never the constraint for training.
CUDA was entrenched in the training phase, and there were no incentives for AI labs to break convention and risk falling behind.
But the arrival of disaggregated inference (prefill+decode, attention+ffn) presented a new opportunity. While the prefill stage was mostly compute bound, the decode stage is entirely memory bound. SRAM is the highest bandwidth memory tier possible, and what better way to get as much of it as possible than to make a chip the size of the wafer. If you want a deeper look at SRAM for inference, see this earlier post.

The end result is that the decode phase of inference is sped up enormously due to the WSE’s memory bandwidth. Since large models require more than the 44GB of SRAM available per wafer, a trillion-parameter model will require multiple WSEs to hold the weights and KV-cache. Since only activations flow between different WSEs, the need for high speed interconnects between wafers is not as much. Various forms of parallelism – model, tensor, pipeline – can be implemented between the different WSEs to implement a full scale model.
While the technology is certainly cool, this level of inference performance is not always necessary. In February this year, OpenAI was reportedly looking to replace 10% of its inference compute with low-latency hardware. The ultra-fast decode only makes sense in a few applications that require real-time performance, or where faster inference literally means money. For most of the inference market, GPU-based inference is the right answer. So like all low-latency inference hardware, this is not a “GPU/xPU killer.”
Yield, Stitching, and the TSMC Lock-In
Wafer scale chips are not a new idea. In the 1980s, Trilogy Systems led by Gene Amdahl famously tried it and failed, concluding that wafer yields need to reach extraordinary levels for this idea to work. The Chip Letter on Substack has a nice series of posts on the history of wafer scale chips (Part 1, Part 2).
Cerebras made it work with a combination of clever engineering that reroutes around to processing units that have defects, to spares on the chip. There are 900k working cores, but closer to a million physical cores on the wafer that are configured at the software level to appear “defect-free.” Cerebras has spent close to a decade with TSMC working out the redundancy schemes, the wafer-level interconnect, and the packaging that makes the WSE physically viable, none of which a competitor can replicate easily. Cerebras has solved wafer-scale chips. You can read all about it here.
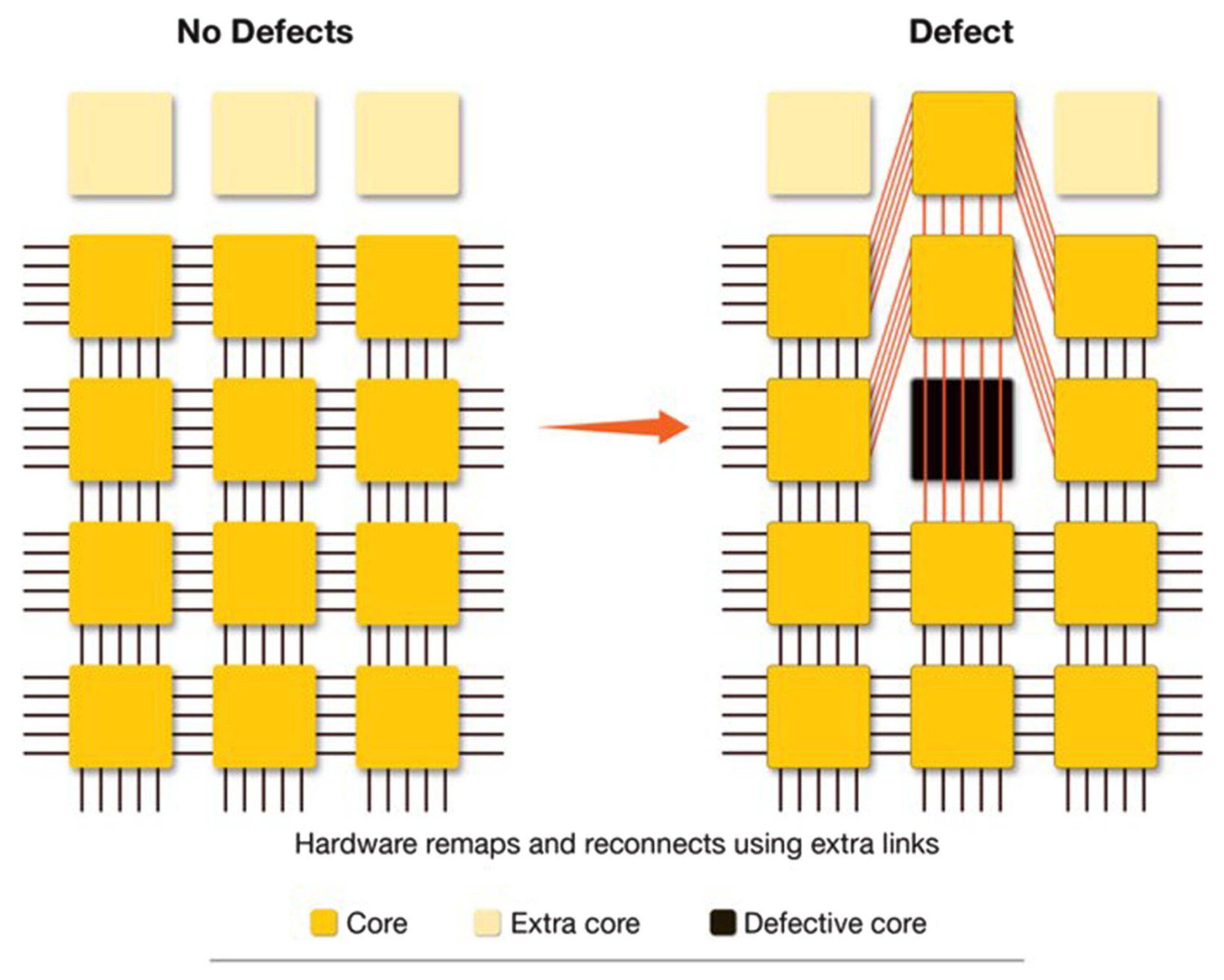
The key point to note here is that the foundry lock-in with TSMC for Cerebras is real. The entire process of stitching multiple reticles together to create a wafer-scale chip is not something that easily translates to another fab that may have better capacity for scale.
The OpenAI Deal: Cloud Service, Not Hardware Sale
The agreement with OpenAI announced January 14, 2026 works like this. 750 MW of compute capacity will be deployed over 3 years, with an option for OpenAI to expand to 2GW total through 2030. The S-1 values the base 750 MW commitment at more than $20 billion.
But OpenAI is not buying hardware. Cerebras is building or leasing the data centers, filling them with WSE-3 systems, and operating them as a cloud service. Several people I’ve spoken to have said that running your own token factory with your own hardware is not where an inference hardware provider wants to be. They’re forced to do so only if people are not buying their hardware directly. Remember that Groq was pushed into selling tokens via GroqCloud as well, until Nvidia came in and paid an extraordinary amount of money to acqui-hire them.
So in reality, OpenAI pays Cerebras for compute time, not for equipment. Cerebras keeps the infrastructure on its balance sheet, recognizes recurring service revenue, and is operationally on the hook for running AI data centers at scale. The financial structure has a bit more detail worth looking at:
OpenAI advanced Cerebras a $1 billion working capital loan at 6% interest, with the interest waived if the loan is repaid through capacity delivery rather than cash. This is effectively prepayment for compute dressed up as a loan, and it funds Cerebras’ upfront capex for building out systems.
Cerebras issued OpenAI a warrant covering ~33M non-voting shares at a near-zero strike price ($0.00001, ok basically free), vesting as OpenAI actually purchases capacity, with full vesting only on the full 2 GW deployment.
As it stands today, Cerebras’ fortunes are tied to OpenAI’s success, and their own ability to deploy and operate at large-scale, which is something they have never done before. Their other source of revenue comes from direct hardware sales to G42 and MBZUAI (in the UAE), and represented a disproportionate share of 2025 revenue (86%). But revenue from running cloud based hardware is expected to be the real growth vector for the future.
The architecture, the deal, and the moat are the publicly debated parts of the Cerebras story. The four risk vectors after the paywall are less discussed and matter more to what puts Cerebras’ ability to scale, in danger.
If you want to work with my boutique research firm, SemiExponent, please send me an email at vik (at) semiexponent (dot) com.