
🍪 TWiC: GaN vs SiC, Wolfspeed, Semtech
A random collection of unfinished thoughts through the week that needs exploring.

This week has been all about the Cerebras IPO, and I’ve been following a lot of the news. I’ve spent a lot of time writing a deep-dive about it and recording a full, Semi Doped podcast episode with Austin Lyons that covers all the details in gory depth. You can find the stack post below, and the podcast should be out this weekend. So we won’t go into it today, but instead investigate some other interesting themes that I’ve been circling this week.
Here’s a recap of content this week:
As part of the Semi Doped ecosystem, we also have a daily newsletter where we post our takes on industry news in the semi space . We are now 1,000+ subscribers strong. So if you haven’t signed up for that, get in on it now.

I want to use this TWiC format going forward to explore undeveloped themes that I am thinking about that will eventually convert into deep dives on this newsletter. Let me know what you think.
GaN or SiC for Power Devices?
There is a question among investors about whether gallium nitride (GaN) or silicon carbide (SiC) is better for power devices, particularly as the industry pushes toward megawatt-scale racks and an impending power wall in AI data centers.
At the fundamental physics level, it does not matter. Both are wide band gap devices, which is a technical way of saying that transistors built from these materials can handle a lot of power before they break down. Depending on the voltage level the transistor can handle, both transistors can be used in power converter applications.
Broadly classifying transistors by material they use is reductive. Take GaN for example: it really depends whether we are talking about GaN-on-Si, GaN-on-GaN, or even vertical GaN. All these affect the voltage handling, and switching speed of these devices (how fast you can turn them on or off).
A lot also depends on which stage of the conversion process you are talking about; closer to the GPU or closer to the grid. A lot of things matter here. We’ll explore all this in a future deep dive. But at the surface level, just know that it's not like one is automatically better than the other.
Why is everyone talking about Wolfspeed?
Remember that this was a company that was in the brink of death just a few months ago. You can check their stock price: it hit $0.5 at some point in the recent past. And, now it’s at about $70. So what’s going on here?
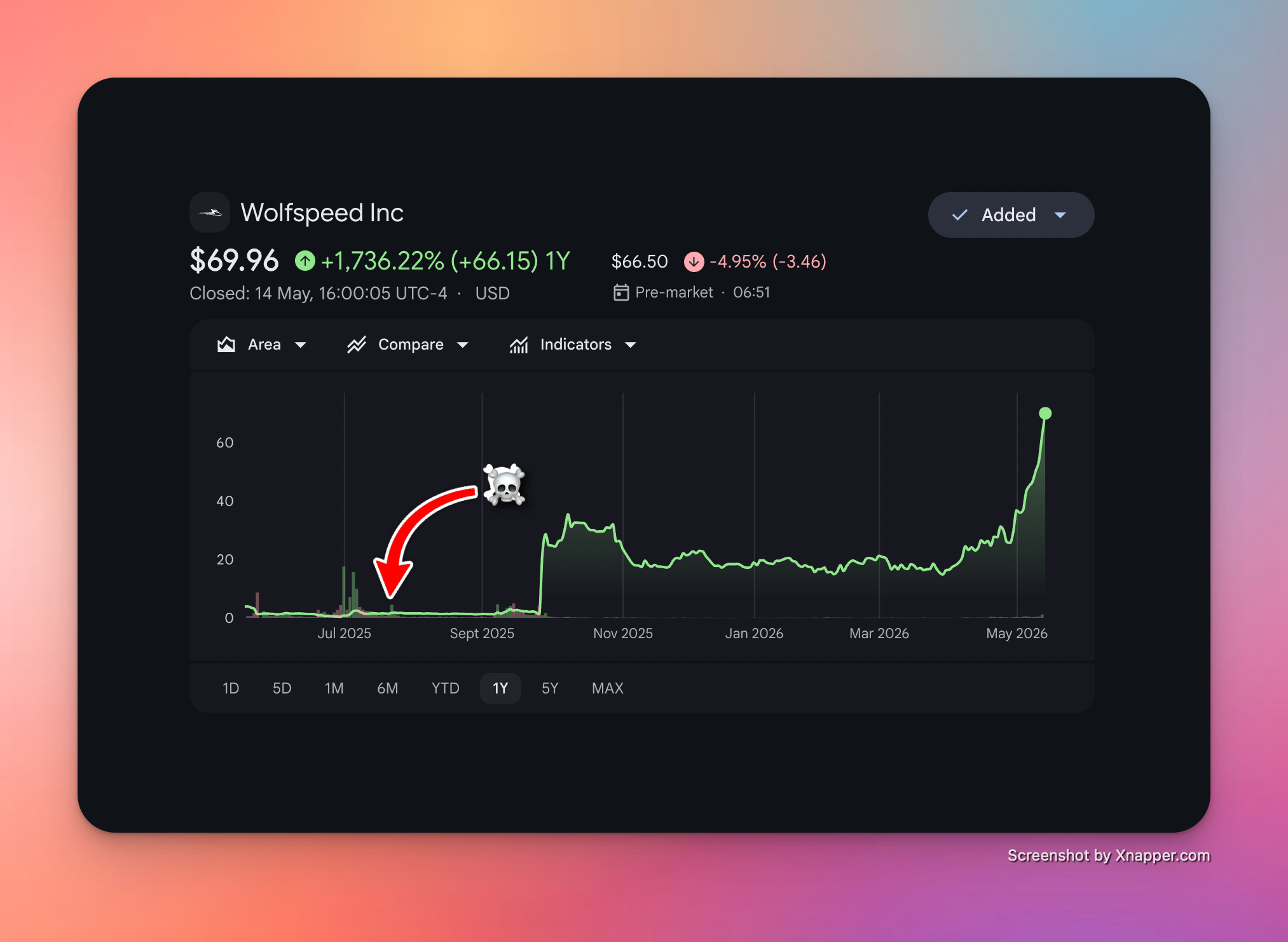
Wolfspeed WOLF 0.00%↑ basically overbuilt SiC manufacturing for EVs and when demand took a downturn, primarily due to massive capacity from China, they were left holding the bags. They even filed Chapter 11 bankruptcy. Mind you, the company is still running at a GAAP net loss of $120M according to recent earnings.
The recent interest in the company, I think, is coming from this one SiC transistor that no one else has. Picture shown below.

This is SiC MOSFET that holds off 10kV of voltage, which is something that only SiC can really do (not sure if GaN can; I haven’t looked). The other alternatives are 6.5kV Insulated Gate Bipolar Transistors (IGBTs) which are silicon based. SiC also switches at a higher speed compared to IGBTs which allows the use of smaller magnetic components in power conversion.
So why is this component so important? You see Medium Voltage (MV) transformers are in very short supply, with backlogs going back 3 years. See this Reuters article, from where I took the screenshot below. This is becoming a serious problem for datacenter buildouts.
What power SiC does here is replace these power transformers that use an iron core and windings with SiC based voltage converters that operate by switching the transistors on and off. This makes for a very interesting use case that deserves looking into. Also, read Irrational Analysis talk about this. The whole interview is great. Citrini also wrote a memo about power semis that really kicked up WOLF stock a notch.
If you’re interested, read this whitepaper from Wolfspeed. We’ll break the tech down in a much simpler fashion in a future deep-dive with wider context.
Semtech CopperEdge
This one is another Irrational Analysis pick from the interview link above, and I’ve had a few people ask me about it. Really haven’t gotten deep into it, but at the surface, it seems like Semtech is a company that was typically known for some IoT and LoRa (long range) stuff that few really care about these days. As it turns out they have a bunch of people who really know how to do analog semis and design some equalizers/redrivers for copper interconnects — the real magicians of semis.

Note that cables when used with Semtech chips will not have DSPs — which puts them more in the class of Active Copper Cables (ACCs) rather than Active Electrical Cables (AECs). I have a post on this from a while ago, if you want to understand it better.

This is crazy to me, because at 200G/lane, I’d imagine you’d need DSPs and pay the power-price for this stuff to actually work. But no DSP? That means straight up power savings — I need to understand this analog magic better. In simple terms, their approach goes something like this:
The degraded analog PAM4 signal comes in.
The chip selectively boosts the weakened high-frequency components (while keeping the overall waveform linear/transparent).
It outputs an amplified, equalized analog signal that the receiver can still understand.
No ADC, no DSP core, no DAC, no re-clocking.
This means, each cable end is <2W or ~1.25 pJ/bit at 1.6T. Most AECs like Credo HiWire are closer to the 20W range per cable end or 12.5 pJ/bit. I am not sure what the power efficiency of Marvell Alaska AECs at 1.6T is, but even if its 2X better than Credo, or 10W per cable end, it’s still 5X worse than what Semtech is saying they can do.
No DSP also means near real time analog latency that is in the 10s of picoseconds (versus nanoseconds with DSPs). This is meaningfully important for the scale up domain where latency matters a lot, in addition to low power.
I’ve got to look into this stuff in a deep dive. Just some off the cuff reaction thoughts when I looked up this thing, and is not an endorsement for the company.
I clearly have lots of work to do here. Let me know how you like the “unfinished thoughts” approach to this edition. Oh, and have a great weekend!
After processing the offload on Cerebras this is what I concluded:
What you’re highlighting here is the real Cerebras story — not the tech, but the scalability physics.
The TSMC lock‑in, the non‑portable reticle stitching, and the fact that the OpenAI deal is effectively a cloud‑service commitment (not a hardware sale) all point to the same thing:
Cerebras isn’t fighting Nvidia or Groq — it’s fighting its own ability to scale a custom architecture.
The tech is brilliant.
The business model is the risk.
Interesting take on Semtech. I glanced at their DesignCon notes for 200G LPO and it appears they are doing some clever tricks to co-optimize the host Tx FIR and module CTLE. I'm not completely sure how the overall power math plays out, but it seems like some of the processing/power burden is pushed to the host DSP. Its still promising though.