
🍪 TWiC: Jalapeno, Modular, and Gatekeeping of Frontier Models
Its all about inference these days, by a long shot.

This week was a big one for OpenAI with ChatGPT 5.6 Sol being released, and their inference accelerator Jalapeno being announced. Qualcomm also held its much awaited investor day ever since they refused to reveal much at Computex. Mainstream news has been all over these topics, but today’s TWiC will cover second-level implications of what these developments mean. I also have a deeper post on Qualcomm hardware in the works.
Here’s what you might have missed this week:
I was traveling in the UK last week, and Austin was in NYC for Qualcomm’s event. We got to recording the podcast later than usual this week, but our entire breakdown of the Qualcomm investor event should be out on the podcast soon.
Reminder that you can keep up with the daily news on the Semi Doped Substack, for free.
Now, on to the news.
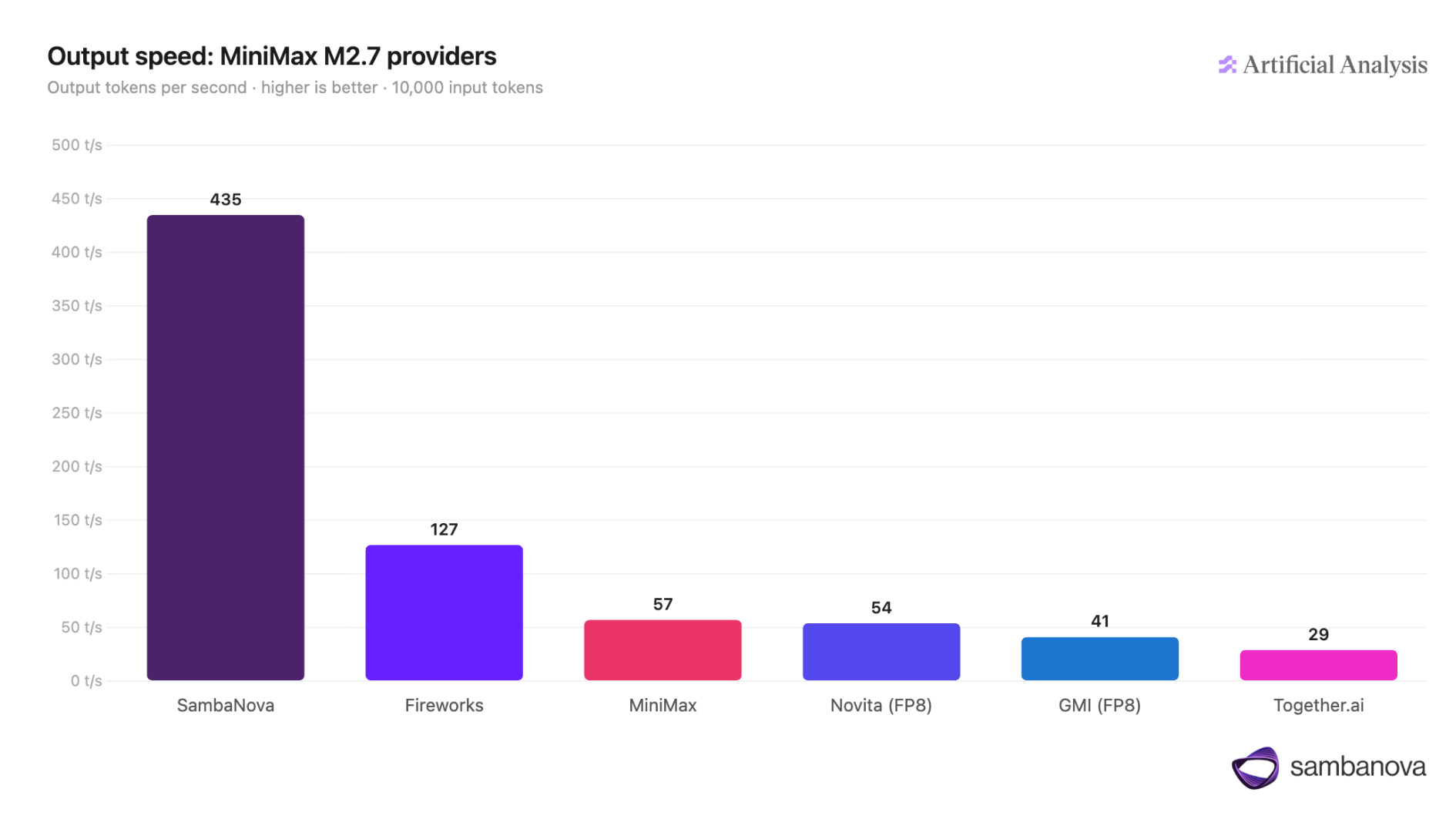
This edition of TWiC is presented by … SambaNova
Run frontier models. Skip the GPU rack.
SambaCloud runs MiniMax M2.7, the fastest provider for this model, at 435 tokens per second via API. M2.7 ranks alongside Claude Opus 4.6 and GPT-5.4 on agentic and software engineering tasks, at a fraction of the cost. No hardware procurement, no lead time, no sharding across hundreds of GPUs.
Texas Advanced Computing Center, OVH Cloud, and Hume.ai are already on the platform. If you’re running long-horizon agent workflows in production, M2.7 is available today on SambaCloud’s Developer and Enterprise tiers. Benchmark your workload against your current provider in an afternoon.
(I tried it for free, and its always using something while knowing what the hardware behind it looks like).
OpenAI’s Jalapeno shows that ASIC design is commoditized
There has been a lot of generic coverage about the fact that OpenAI has their own chips, but I want to point out one thing: this chip was made with Broadcom doing the ASIC design from start to finish in 9 months. That means one of two things: (a) Broadcom’s silicon prowess is what Hock says it is — amazing, or (b) ASIC design has become a commodity business, with no moat after all.

I am willing to bet on the latter. The process of wafer fab and packaging usually takes about 3-4 months from start to finish. If you can one-shot a cutting edge inference chip in a mere 5-6 months, it shows that its probably easier to make than most people think.
I have personally never done ASIC design so take my words with a grain of salt, and feel free to correct me. But I do know that engineers working on that largely deal with software only. Coupled with the fact that AI-enabled design flows are now being pushed by every major EDA company, maybe chip design is getting commoditized after all — the press release does say “accelerated by OpenAI models.” But, not all kinds of chip design are easy: optics, power, analog, and anything that does not rely on digital transistors turning on and off, are still challenging to make and require specialized expertise. CPU design is still challenging perhaps — I don’t hear of anybody doing that in 9 months. Just some observations.
What does Modular bring to the table for Qualcomm?
Qualcomm recently announced that they will be acquiring Modular in their recent Investor day. But why is a company like Qualcomm buying a software platform like Modular?
Qualcomm is betting on disaggregated inference, which means that the future of AI involves a mix and match of hardware, each suited to the best function and workload. Imagine that you can get a DragonFly rack from Qualcomm, a low latency inference rack of LPUs from Nvidia, and a CPU rack from AMD. How do you ensure that they all work together?
This is what Modular brings to the table. One software platform for different kinds of hardware. To work with the Modular layer means that the software stack is written with Mojo. If NVIDIA CUDA is like Apple’s iOS, then Mojo is like Android. No need for specialized hardware tied to the software, but instead work with every hardware provider possible. These kernels written up with Mojo is then served with MAX on your own cloud platform, or you could use Modular’s.

But if Modular is owned by Qualcomm, how does a purchaser of a Qualcomm DragonFly rack deploy actual services? Do they pay Qualcomm a royalty fee for the software layer? Are they even willing to adopt the “Android of AI Inference” in order to deploy Qualcomm racks? A lot of these questions remain and remains unclear until the hardware actually lands.
The Gatekeeping of Frontier Intelligence Models
ChatGPT 5.6 “Sol” was released this week, and the full capabilities of the model are only available to a select few. The Trump Administration has “requested” a staggered roll out, ask that it approve its use on a case-by-case basis, as reported by The Information. This is a much more favorable deal for OpenAI than what Anthropic got even with its nerfed Fable model. Mythos was never meant for public consumption from the get go.
Gatekeeping frontier intelligence models creates an opposing tension; on one hand, it creates a layer of resistance to monetize the newly trained model in an AI token factory, but on the other, the industry does not have enough compute to serve frontier intelligence at scale. The path to usefulness of AGI is always limited by how many chips we can actually make. These opposing tensions place frontier models in a neutral equilibrium: a restricted user base on a finite supply of compute.
This disturbing trend of AI governance opens the door to many future questions:
Would OpenAI or Anthropic dedicate enough resources to develop the next frontier model knowing a-priori that its full capabilities are going to be restrained?
Who decides who gets to use cutting edge models, and does that give them an unfair advantage over competitors?
If model releases depend on the benevolence of political leaders, what levels of quid-pro-quo can we expect to see between Silicon Valley and the White House?
Model scaling laws still hold: adding more compute to training a model creates better models, but human laws are a limiter. The imperative now shifts to model labs to instead continue to monetize via AI inference where the real economic value lies. The bodes well for the smorgasbord of interference accelerator companies who rely on interference to be the main driver of silicon demand. Today, NVIDIA is the dominant provider of training chips, and a slow down in frontier model progress due to governance will also slow down the consumption related training hardware.