
What AI Inference Actually Demands From a NAND SSD
KV cache storage is a distinct workload that requires SSDs designed for it. Number of cell levels, block sizes, and data placements all matter, and some SSD flash makers are actually getting it right.

Earlier, we have covered NAND as a storage tier, and what its importance is in an AI datacenter. It was a broad post introducing various technologies in use for those not familiar with storage technologies. You can read that below as a precursor to this article.

However, at the recent Computex event, I had an interesting chat with some investors who were interested in knowing if SLC NAND was making a comeback because write endurance of TLC/QLC NAND was worse, even if it had more capacity. The answer to this is nuanced because it is no longer sufficient to think of NAND as a single tier, but instead how NAND is starting to split into multiple sub-tiers based on its place within the memory hierarchy, each with its mix-and-match of technologies.
The broader question that it encompasses is what the performance expectations of NAND in these newly forming performance tiers are, and more importantly what products from which companies are well positioned to capture the upside.
In this post, we will explore how NAND SSDs fit into context memory storage (or CMX, as NVIDIA calls it), and look at which SSD vendors are best positioned to serve this market.
Here is what we will cover:
Why NAND SSDs are a viable option for AI inference
Tuning SSD Performance for Memory or Storage
CMX-Specific SSD Optimizations
I/O size and the indirection unit (IU)
Asymmetric read/write bandwidth
Write Amplification and FDP
NAND SSD Competitive Landscape
By reading this post, you agree to the terms and conditions. Also see the full ethics statement.
If you are not a paid subscriber, you can purchase just this article. This post will be updated with a direct purchase link shortly; check back on Substack.
You can find the whole catalog of articles for purchase at this link.
If you would like to engage boutique research services for your project, reach out to us.
Why NAND SSDs are a viable option for AI inference
Relying solely on DRAM (including HBM) to hold context is becoming untenable in the agentic era of inference due to cost and capacity. As users delegate increasingly complex tasks to AI, inference is no longer a process that takes minutes; it is extending to hours and days, and if we could manage it, to weeks and months. “Hardware-utilization-factor” will become an increasingly important metric as neoclouds and hyperscalers grapple with large capital expenditure costs while trying to translate investments into revenue. Underutilization due to memory capacity constraints is an unacceptable scenario.
NAND SSDs are a viable alternative because their performance can be finely tuned to act more like memory, or more like storage, depending on the underlying technology used. What was once a means to just faster storage and an alternative to HDDs, is now becoming a memory tier that lies somewhere between storage SSDs and DRAM.
The primary function of NAND in the agentic AI era is to hold KV-cache, which can often balloon to tens of TBs over the course of a large agentic task, eliminating the possibility of storing it on any DRAM tier. During the decode step of inference, the KV-cache needs to be accessed as fast as possible to provide a high token throughput. Speed is especially important because the decode step generates one token at time due to the autoregressive nature of the transformer architecture. NAND SSDs, with the right modifications, are capable of serving as a KV-cache store while streaming data fast enough for decode to still work well.
DeepSeek v4, for example, has already made NAND a first class citizen by ensuring that context is offloaded to SSDs and cache-hits are maximized for the lowest possible token cost. It is highly likely that similar architectures will follow in other models.
Aside: CXL pooled DRAMs are equally viable, and some would argue a better alternative, but that’s a different post. In reality, it occupies its own tier in the memory hierarchy.
Tuning SSD Performance for Memory or Storage
The feasibility of NAND for AI inference stems from the design choices of the underlying flash cells. While my original NAND article covers the in-depth workings of the various types of NAND, we’ll address it briefly here, and focus more on how to slot them into different NAND performance tiers.
Flash memory essentially operates by storing or releasing charge, which represents the bit representation of 0 or a 1. An N-level NAND cell has 2^N states in which a memory cell can exist in. For a single level cell (SLC, N=1), there are just two states. For a quad-level cell (QLC, N=4), there are sixteen states. The capacity increases when more states are stored in the same cell because the cell physically does not take up any more space where it stores a 0/1 in SLC or 0000—1111 in QLC. In other words, you can store more bits in the same physical area.
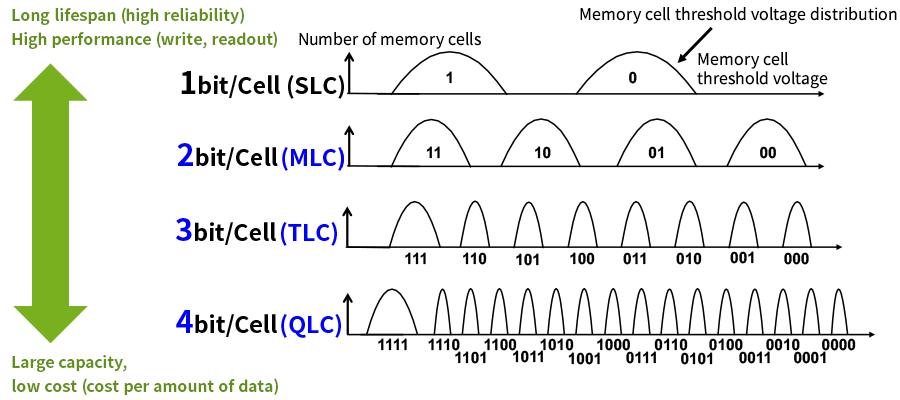
Capacity increase comes with other trade-offs, namely endurance and speed – and both of which are tied to the number of cell states. It comes down to distinguishing between either just two cell states or sixteen, and how that can be done quickly and reliably over the life of the NAND SSD under all operating conditions it is subject to.
Endurance: Over time, the voltage levels that distinguish between the cell states start to move due to constant cell writes and temperature effects over time. It is just part of the wear and tear induced in the oxide layers within the cell when it is subject to constant use over its lifetime. For a single voltage level that distinguishes between cell states (like in SLC), the shift can be higher and we can still tell if the cell holds a zero or one. For a QLC with 16 voltage states, it becomes much harder, and guessing wrong results in a bit error. Once bit errors increase beyond a certain threshold, the NAND SSD is deemed worn out.
Write Speed: Writing to a cell involves finely adjusting the voltage applied to the cell, and closely monitoring the resulting current from the underlying cell. To determine what the state of the cell is, a process called incremental step pulse programming (ISPP) is used to recursively adjust the voltage to just the right level (more in the original NAND article). This iterative process of adjustment affects the write speed because it takes many recursive steps to set the right voltage. With fewer cell states, the iterative process is quicker which means SLCs are faster than QLCs.
By now it should start becoming clear how NAND SSDs can be fine-tuned for capacity and performance, at least to the first order. Use more cell states (higher level NAND) to get more capacity, but fewer cell states (lower level NAND) to get more speed/endurance. A hybrid approach is also possible: use a SLC-cache with a TLC NAND, for example, to get the best of both worlds with the right speed/endurance/capacity tradeoffs.
Next, we will discuss how NAND SSDs are better optimized for AI use-cases, and conclude with a competitive survey of the NAND landscape for agentic AI.
Beyond the paywall:
CMX-Specific SSD Optimizations
I/O size and the indirection unit (IU)
Asymmetric read/write bandwidth
Write Amplification and FDP
NAND SSD Competitive Landscape