
Beyond GTC: A Deep Dive into Compute, LPX, and the Untold Story of SpecDec
Analyzing the CPU, GPU, and LPU chip ratios unveiled at the Nvidia GTC keynote, the impact of the Groq LPX chip on disaggregated decoding, and its potential for speculative decoding in AI inference

The Nvidia GTC keynote was a much anticipated event. Austin Lyons of Chipstrat and I had a quick chat with our unfiltered takes on the same day as GTC, on the Semi Doped podcast. Check it out.
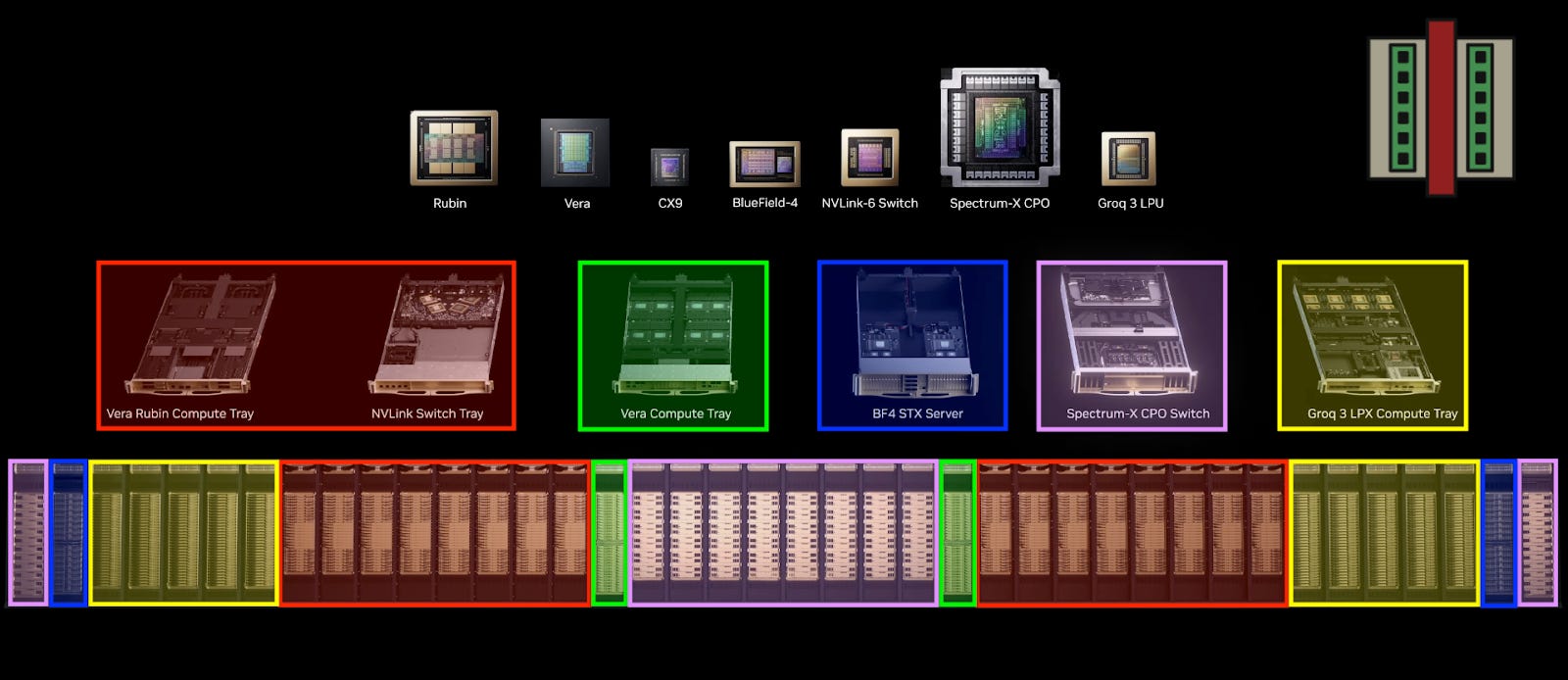
With the introduction of the Groq LPX chips, Vera-Rubin has 7 different kinds of chips that can all be integrated into racks that comprise the entire system. The keynote highlighted where each of these racks go in the entire pod, which I color-coded as shown below. This pod architecture reveals quite a few interesting details which we will explore in this post.
We will discuss:
How CPU-GPU-LPU ratios are scaling
Understanding disaggregated decoding using LPX
The new frontier of inference speed unlocked by LPX
After the paywall:
What went unnoticed at GTC: Speculative decoding on LPX
Does VLIW really matter after all?
If you are not a paid subscriber, you can purchase just this article using the button below. You can find the whole catalog of articles for purchase at this link.
Counting Compute: CPU-GPU-LPU Ratios
The CPU utilization comes from two places: (1) 2 Vera CPUs per GPU tray, and (2) 8 Vera CPUs per CPU tray. From Jensen at GTC:
We never thought we would be selling CPUs standalone. We are selling a lot of CPUs stand-alone. Already, for sure, [this is] going to be a multi-billion dollar business for us.
Knowing the configurations of the xPU trays and construction of the superpod, let’s calculate how compute scales:
2 Vera CPUs per 1U GPU tray, 18 GPU trays per rack, 16 racks = 576 CPUs.
8 Vera CPUs per stand-alone CPU tray. There are 32 CPU trays per rack, and two stand-alone CPU racks. That gives a total of 8 CPUs/tray × 32 trays per rack × 2 racks = 512 CPUs.
Thus, the total estimated Vera CPUs per super pod is 576 + 512 = 1,088 CPUs. There are 4 Rubin GPUs per 1U compute tray, 18 trays per rack, 16 racks = 1,152 GPUs.
There is a third location where CPUs are needed. For every Groq tray containing 8 LPX chips, there is another CPU host that needs to be accounted for – the host CPU. The picture below shows the LPX rack on the right, with 32 compute trays per server, and ten such racks in the pod. So let’s add these chip counts in:
LPU: 8 LPUs/tray × 32 trays/rack × 10 racks = 2,560 LPUs
CPU: 1 CPU/tray × 32 trays/rack × 10 racks = 320 CPUs

Interestingly, the CPU in the LPX tray is not a Vera CPU because they likely need x86 chips from the GroqNode architecture that used dual socket AMD EPYC CPUs.
All in all, we have the following compute units now: 1,152 GPUs, 1,408 CPUs, 2,560 LPUs. In our earlier discussion below about the rise of CPUs for agentic AI, we predicted that CPUs might exceed GPUs at the rack scale. Additional CPU racks are straightforward to deploy since they only need ethernet connectivity, not the high-bandwidth interconnects required for weight transfer.

A final detail that requires a mention is that the LPX compute tray contains an FPGA (likely Intel/Altera), whose main purpose is to provide the logic operations to expand the memory fabric to DRAM. The LPX supports up to 256 GB DRAM expansion via the FPGA, and up to another 128 GB via the host CPU DRAM. My guess is that the first tier of DRAM uses an FPGA to retain the memory bandwidth as much as possible when data is offloaded to it. Relying on the scheduler on the CPU host is almost always slower. It is not entirely clear if the FPGA also does the orchestration of Groq LPUs.

Disaggregated Decoding Using LPX
In a previous article we published pre-GTC, we discussed the implications of SRAM-based accelerators for decode operations. In the light of more Groq details, we can extend this discussion further.

At GTC, Jensen was specific on the use-case of SRAM accelerators for the feed-forward network operation of the decode process. In September 2025, the GDDR7-based Rubin CPX was announced for disaggregation of prefill, but that narrative has largely been lost with a lot of confusion if LPX has replaced it instead.
But this is comparing apples and oranges: the LPX is bandwidth optimized hardware for decode while the CPX was designed to be more FLOPs-heavy for prefill. The real question is if separate hardware like CPX is required for prefill, or if it can just be handled by the HBM-based Rubin. Now, the decode phase is disaggregated further.
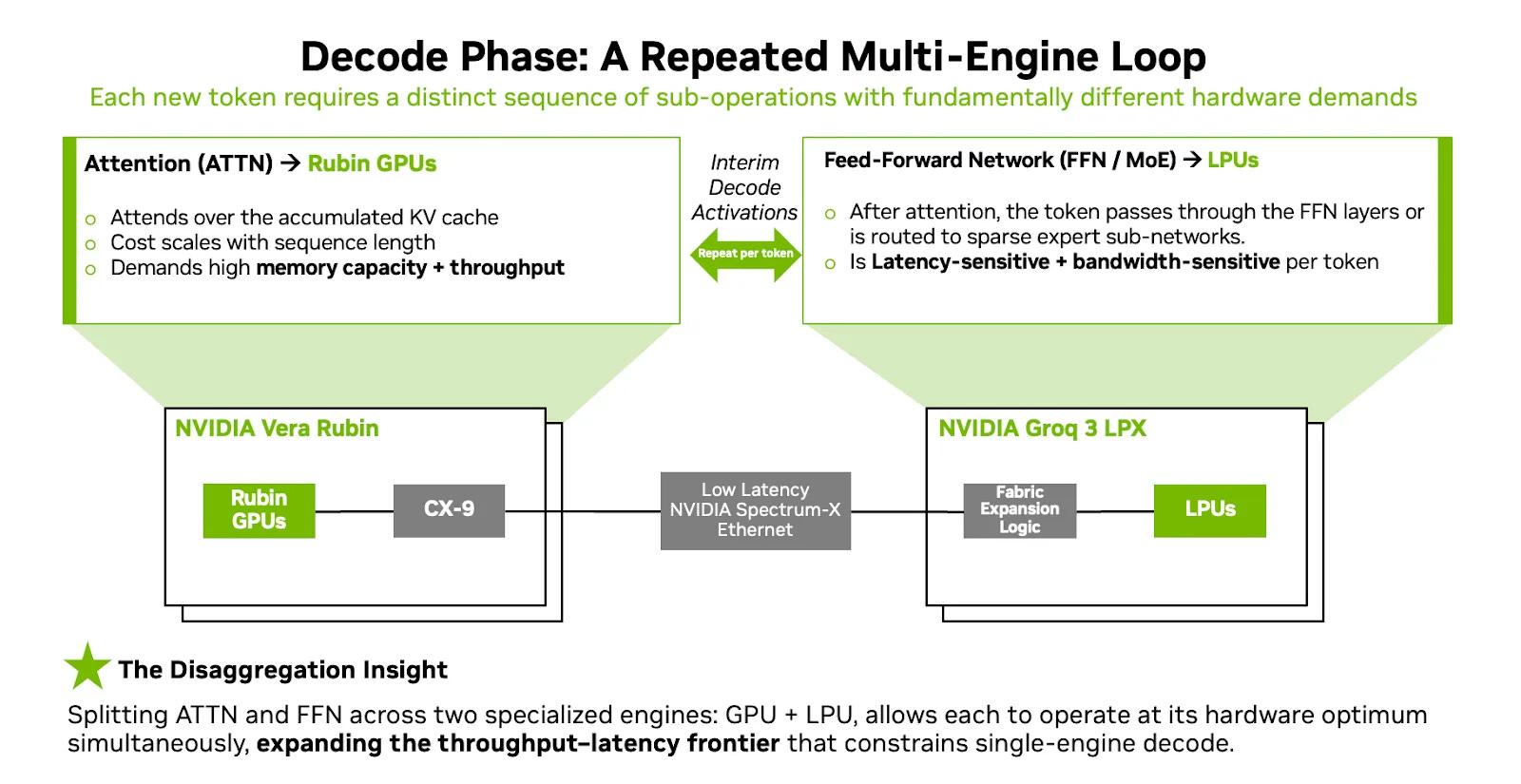
The decode phase involves the calculation of attention, followed by the Feed-Forward Network (FFN). HBM-based Rubin GPUs are the best candidate for autoregressive attention calculation because the tokens are generated one after the other, in sequential fashion. The KV cache grows with input tokens and is best stored on HBM, and as a result, the demand for HBM will continue to stay.
The FFN calculation, on the other hand, is a giant matrix multiplication that lends itself to parallelism. The matrix can be sliced into smaller pieces across many chips (tensor parallelism), computed independently, and reassembled later. MoE models take this further because each expert can live on its own set of chips (model parallelism), so you don’t need one chip to hold everything.

The latter FFN/MoE phase is what the Groq LPX is meant to address. Nvidia has put in a high density of eight chips per LPU tray because each Groq 3 has only 500 MB of SRAM. So 2,560 LPUs in a super pod gives 1.28 TB of SRAM capacity at 150 TB/s memory bandwidth per chip (~384 PB/s at rack scale). That gives plenty of capacity to hold the FFN weights of a large model, which incidentally occupies two-thirds of all weights in a model.
The transfer of weights and KV cache between the attention calculation on Rubin GPU and the low-latency decode hardware on LPX is done with Spectrum-X ethernet, although Infiniband could be used as well presumably.
A New Frontier of Inference Speed
The addition of LPX racks unlocks a new token generation speed that was previously impossible with just GPUs alone. The graph below shows the token throughput on the y-axis - a measure of how many tokens/sec can be generated (normalized to power), versus interactivity on the x-axis - a measure of the user experiences speed in terms of tokens/sec available per user. Ideally, we want to be on the top right of the chart, but this is usually not possible due to simultaneous compute and memory bandwidth limitations.
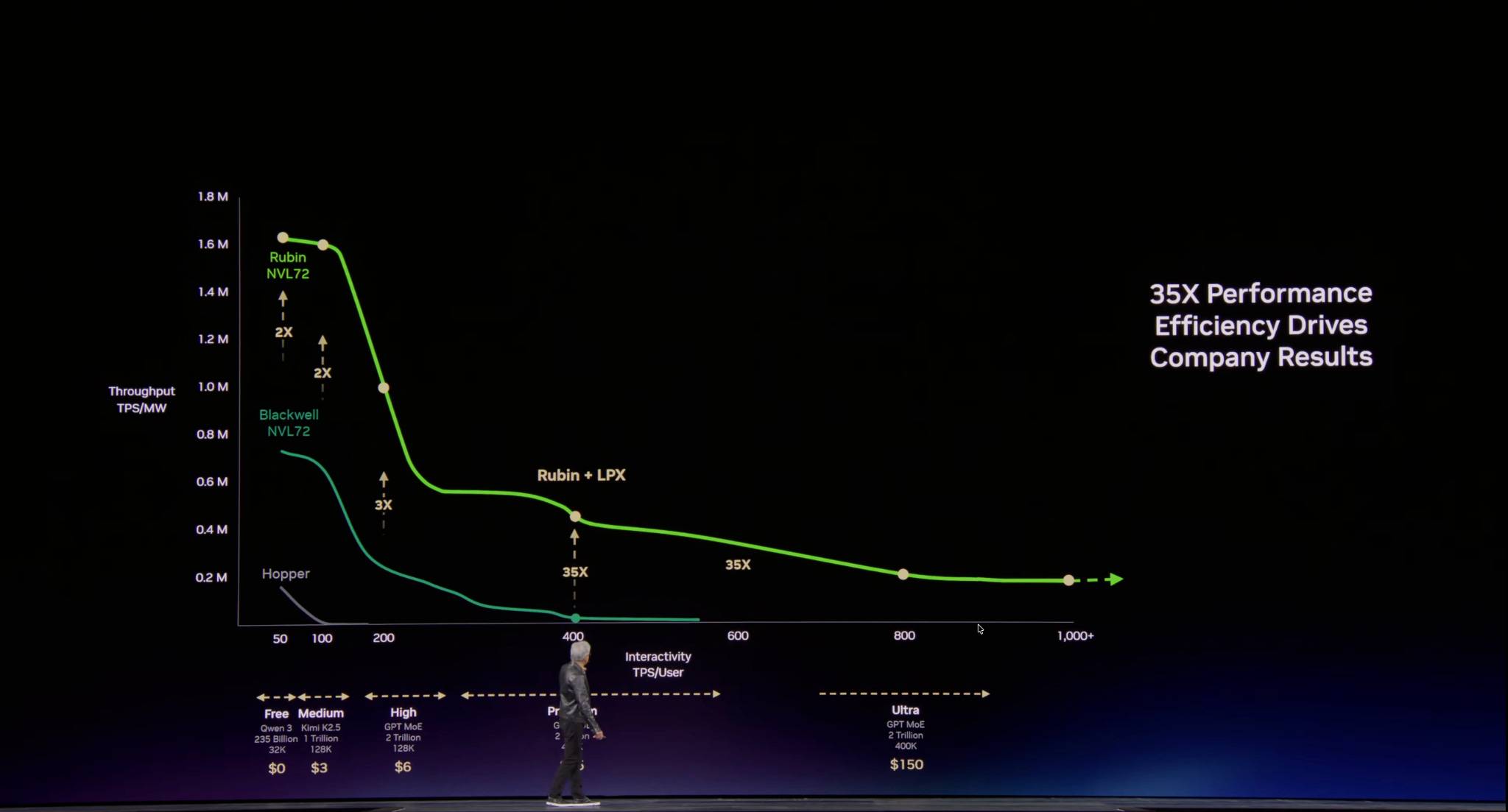
The introduction of LPX pushes the frontier of what is possible in terms of inference speed, with an advertised 1,000+ tokens/sec/user. This is why the licensing of Groq technology was a critical piece of technology necessary for Nvidia; one that they did not have with their GPU family of chips. Most importantly, Jensen explains how to deploy AI infrastructure based on expected workloads:
For a lot of high throughput activity that does not require low latency → stick to Vera-Rubin NVL72
For low-latency, “time is money” kind of applications like coding and engineering → deploy up to 25% of LPX along with Vera-Rubin.
In this context, it is not clear what 25% means: number of chips? Total memory? A better metric is to understand how many LPX racks should be deployed to set a desired interactivity level.
Speculative Decoding on LPX
To be honest, I was expecting Nvidia’s announcement at GTC to be centered around the acceleration of speculative decoding (SpecDec). Instead, it was more of a plain vanilla attention/FFN disaggregation. This is likely because SpecDec is an inference technique crossing from research to early production. Meta, Groq, and a few other labs have looked at it in detail, but it is far from standard infrastructure at the moment. However, I do believe that LPX has massive benefits for SpecDec which was completely unaddressed in the keynote.
After the paywall, we will discuss what Nvidia did not:
What went unnoticed at GTC: Speculative decoding on LPX
Does VLIW really matter after all?