
Inside SambaNova's Inference Architecture
How the Three-Tier Memory Hierarchy and the Reconfigurable Dataflow Unit Compare to Rubin, Groq, and Cerebras

We are in the “Wild West” of inference accelerators. While Groq’s VLIW approach and Cerebras’ wafer-scale engine have been in the news lately, the landscape of inference accelerators is technologically diverse. The current way of deploying frontier models is to have a trillion-parameter-scale model split across several chips that work together to perform inference.
GPUs are packed with HBM, and during inference, the model is sharded across multiple GPUs.
Groq’s LPUs with their hundreds of MB of SRAM require thousands of chips to run a large-scale model.
Cerebras can hold up to 44 GB per wafer in SRAM, but requires the problem to be distributed to multiple wafers for large-scale model serving.
SambaNova has a different take on the problem.
What if, instead of a single large Mixture-Of-Experts (MoE) model, you built a composition of many smaller experts, each trained to be competitive with monolithic MoE model experts? Think of 100+ 7B parameter models all doing one thing really well. This is what SambaNova calls Model Bundling, which was the initial motivation for the architectural choices that Sambanova’s hardware is built on.
In this post, we will discuss SambaNova’s 3-tier memory architecture, their Reconfigurable Dataflow Unit (RDU), and how they compare to more recent hardware architectures in the news like Nvidia’s Rubin, Groq LPUs, and Cerebras wafer scale engines.
Specifically, we will discuss:
The Three-Tier Memory Architecture
Understanding how RDUs work
Scaling up to the rack level
Where SambaNova fits
SambaNova vs Rubin
SambaNova vs Groq vs Cerebras
Where does this leave SambaNova
Disclosure: This is not a sponsored post. SambaNova provided their inputs on a draft version of this post, primarily on their use cases and nomenclature which has been incorporated into the post. Opinions are my own.
If you are interested in other inference hardware deep-dives on this newsletter, check these out:




If you are not a paid subscriber, you can purchase just this article using the button below. You can find the whole catalog of articles for purchase at this link.
The Three-Tier Memory Architecture
Let’s say you have a bunch of small models tuned to do one thing really well. Each “expert” could be a coding model, a writing model, a sales model, and so on. To quickly switch between these experts, each expert’s weights need to be stored in high-capacity memory (like DDR) that can be quickly swapped into a faster memory tier (like HBM) with latencies in the microsecond range, and the hottest weights loaded into SRAM. This is what SambaNova’s 3-tier memory architecture is built to do; all tiers are addressable directly from the chip, each with their specific function.
Per model layer scratchpad: On-chip SRAM (several hundred MB per chip)
Working model weights: CoWoS-attached HBM (several tens of GBs per chip)
Cold storage of model weights: DRAM (1 to 2 TB) on the board level per socket.
Loading these weights from network storage over InfiniBand is too slow for frequent back-and-forth trips between different expert models serving different tasks. The three-tier hierarchy gives you a lot of memory and keeps all of it close enough to compute to be useful during inference. SambaNova is not the only startup to envision multiple memory tiers for inference. MatX, for example, uses a mix of SRAM and HBM. d-Matrix uses a combination of SRAM and 3D DRAM. All of them have different approaches to solving the memory bandwidth problem.
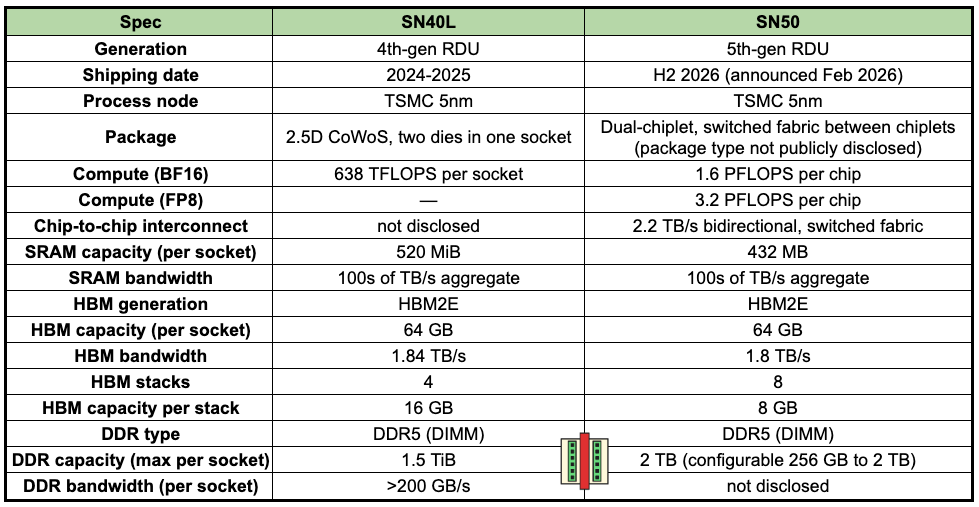
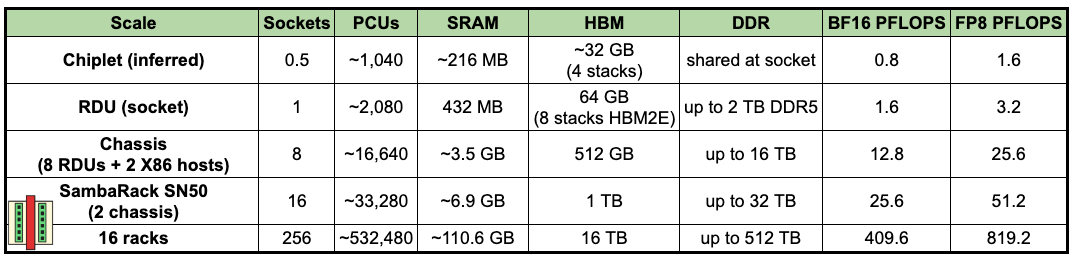
The table below shows the specifications of different memory tiers in SambaNova’s last two chip generations: SN40L and SN50. A key point to note is that the SN50 actually went back a generation in HBM: from 3 to 2E. Edit: SambaNova pointed out that both SN40L and SN50 are on HBM2E while also being on TSMC 5nm; the table below reflects that. But, there is an actual architectural reason why HBM bandwidth does not always matter for SambaNova. We’ll get to this later.
To really understand how this memory architecture works with either model bundling or true MoE models, we need to understand how RDUs work first at the chip level, and then at rack scale. This really matters for how data flows through the system.
Understanding How RDUs Work
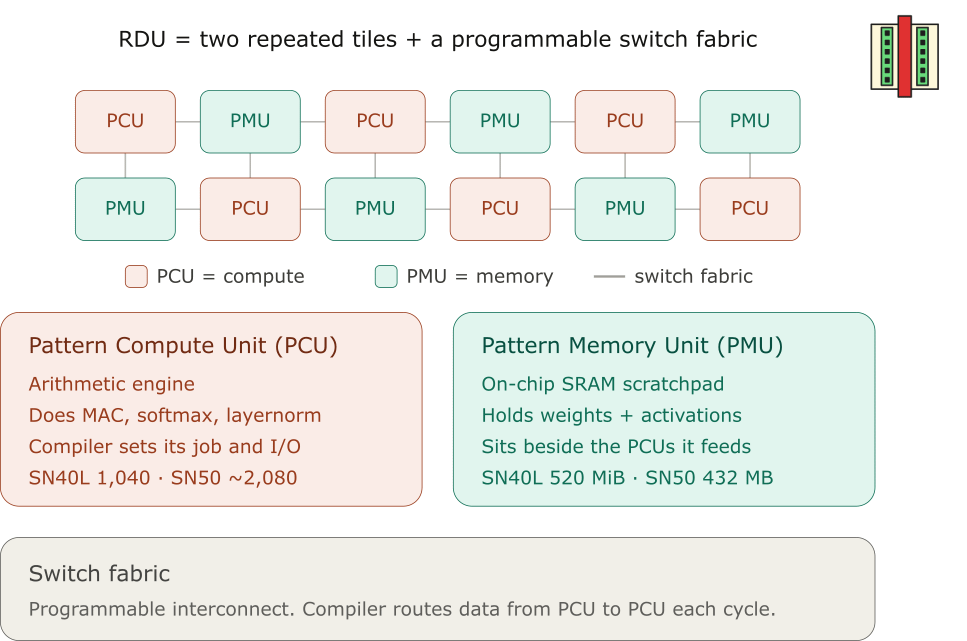
A reconfigurable data unit or RDU is just two primitives that are repeated many times on the chip, and wired together with a programmable switch fabric. The two primitives are:
Pattern Compute Units (PCUs): These are the arithmetic engines. Each PCU can perform multiply-accumulate operations, perform softmax operations for attention calculation, or layernorm operations. The compiler decides ahead of time what the PCU does, and what flows in and out. SN40L has 1,040 PCUs per socket (across two dies); SN50 has roughly 2,080 PCUs per socket (across two chiplets).
Pattern Memory Units (PMUs): These are the on-chip SRAM scratchpads. PMUs hold the weights and activations that feed the surrounding PCUs. The 520 MiB of on-chip SRAM on SN40L is spread across 1,040 different PMUs. Same arrangement on SN50 (432 MB across ~2,080 PMUs). Each PMU sits physically next to the PCUs that read from it, so the bandwidth between scratchpad and compute is local and short.
The switch fabric is a programmable interconnect that wires PCUs and PMUs together. The compiler determines what data moves from one PCU to another over the fabric at any given time.
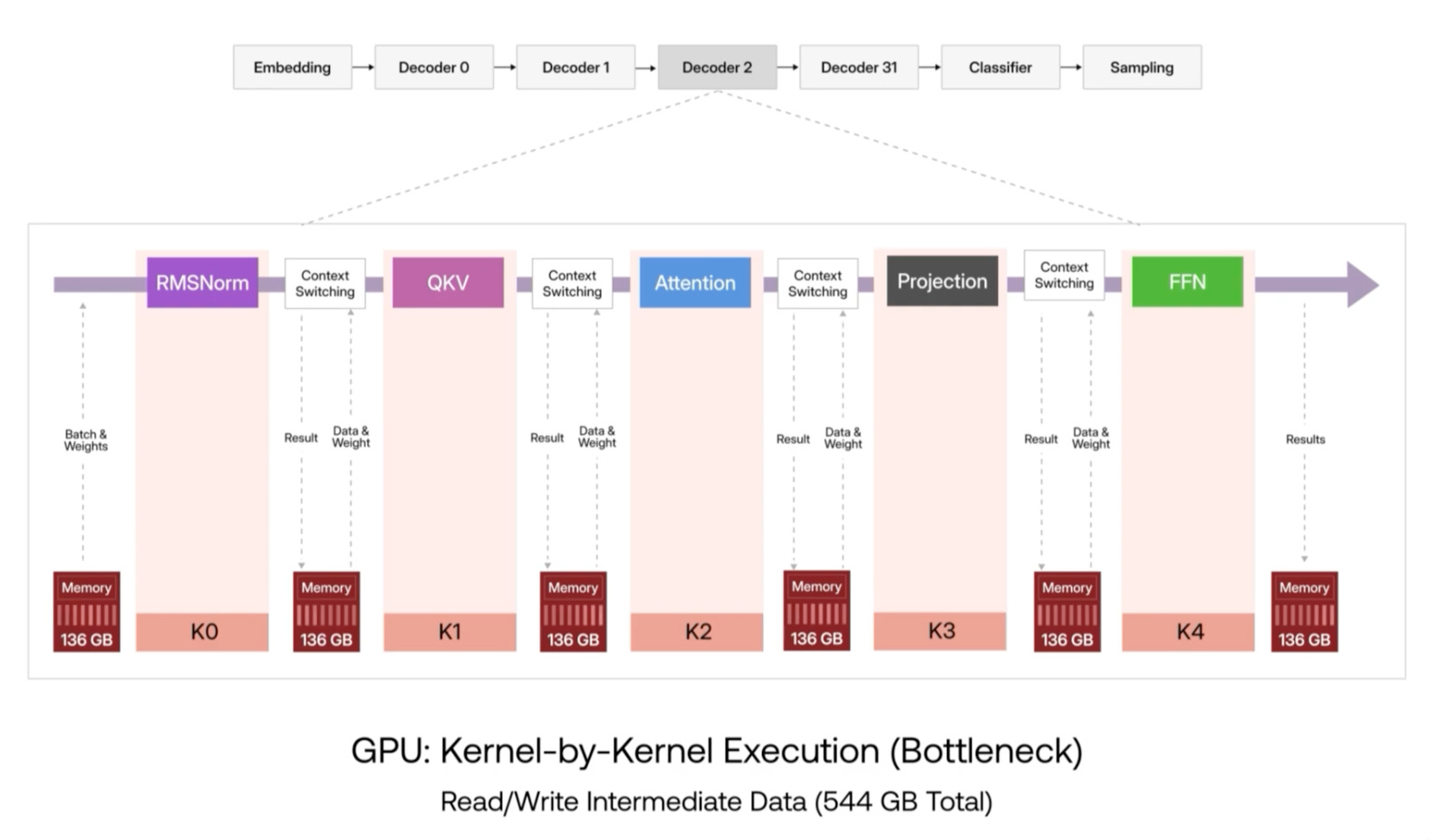
To show how the RDUs sharply differ from a general purpose GPU, we must understand how computations are done on both, and where the RDU shines.
Here is how the process of inference works in a GPU. Each operation (or kernel) in the process of inference is written to HBM and then read back for the next step in the calculation. The figure below shows this in more detail. First, RMSNorm is calculated and the result is sent to HBM. Then, all the info along with weights is read back for QKV calculation and so on. The problem with this approach is that there are a lot of memory accesses along the way which increases latency, and burns more power shuffling bits in and out of memory.
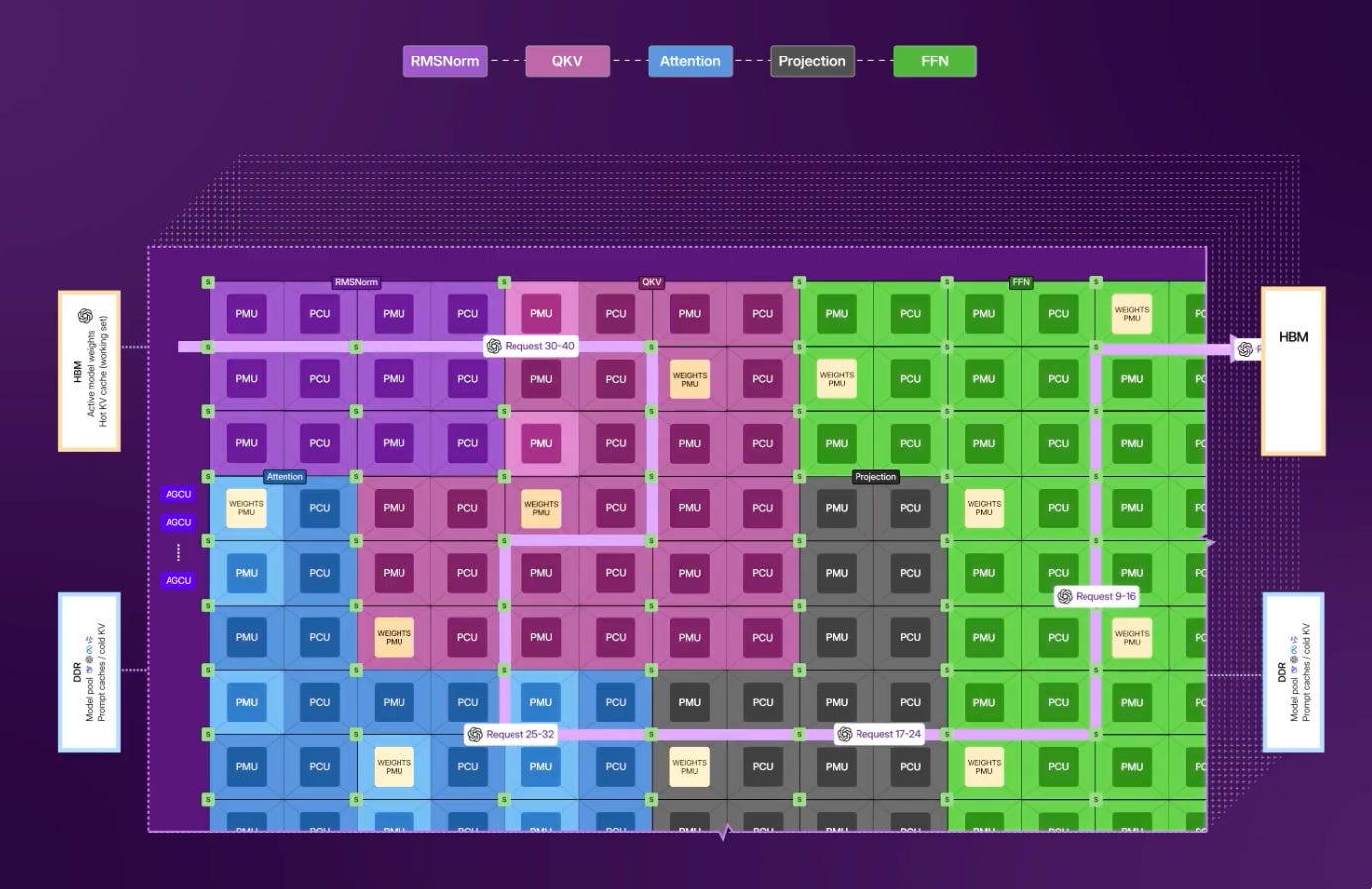
Here is how SambaNova does it: They assign all the PCUs and PMUs on the chip to various parts of the inference process. As shown in the image below, you can literally gerrymander your way through memory and compute cores via the software compiler. The computations are done on the PCUs, and the intermediate weights and results are stored in the PMUs. In a sense, the SambaNova compiler predetermines the “dataflow” across the chip – that is, how to split up the available data units to perform different functions required for inference.
By keeping the entire calculation process on the chip, the data never leaves the chip to external HBM memory. HBM is only present to load up the weights into PMUs, and is not really used in the computation process. This explains why SambaNova can get away without using the latest HBM4 or HBM4e because their architecture simply does not demand extreme memory bandwidth from HBM. All relevant data for inference stays on the chip, and when something more is needed, it is read from HBM. They can however, still benefit from HBM4, as we will see later.
Scaling up to the Rack Level
Now this is just one chip, and you might be thinking that a few 100 MBs of SRAM is not going to cut it. The real picture starts coming together when you look at it at scale. Each “SambaChassis” (my name for it, not SambaNova’s) has 8 RDU chips, and two x86 CPUs – likely Intel Xeon 6s, from the looks of it, based on recent partnership announcements. You can put 2 chassis per rack, for a total of 16 RDU chips.

This entire rack acts as one giant chip, and you can basically break up the process of inference across all of them in any slice-and-dice way you want because they are all on the scale-up fabric. You can route your datapath through any of the RDUs across the entire rack.
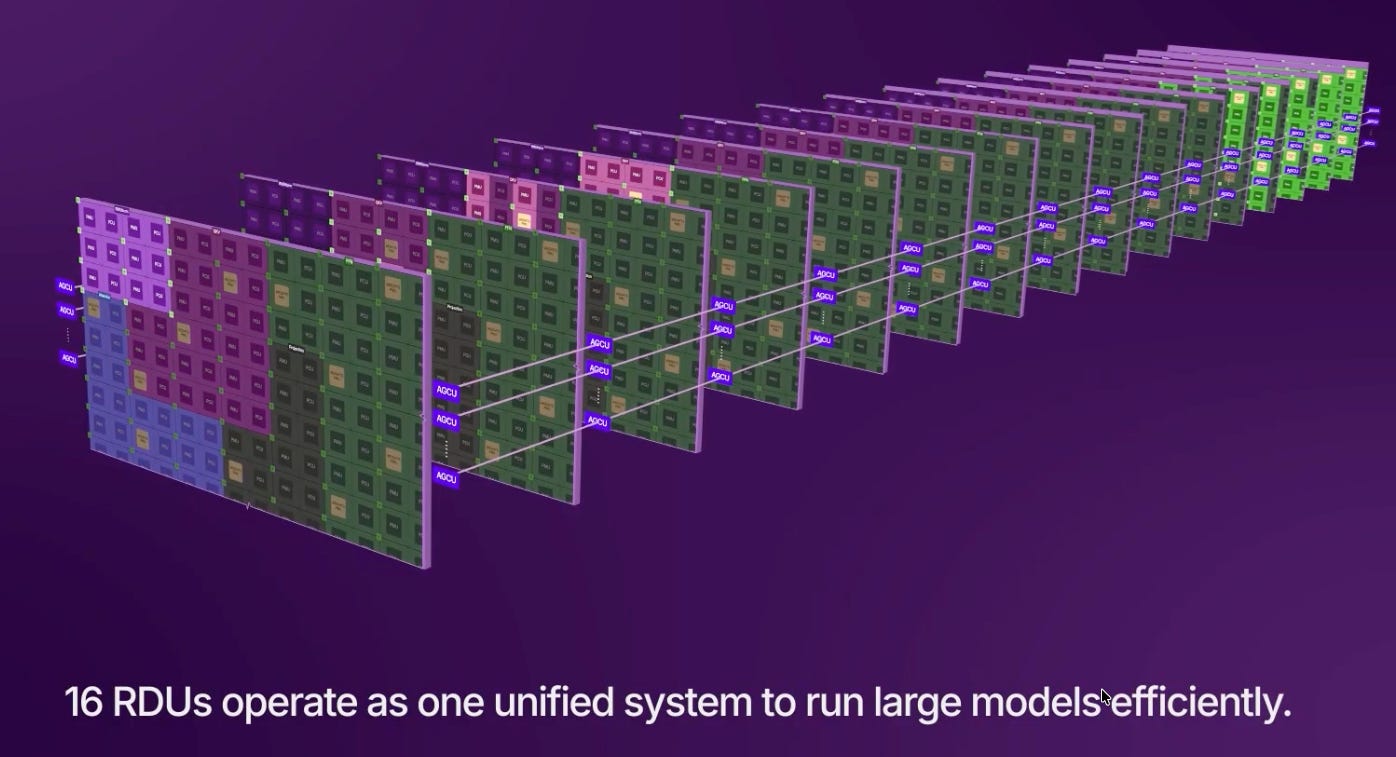
Across a rack, you get ~7GB of SRAM and 1TB of HBM. Arguably, this is significantly less than Cerebras WSE’s 44GB per wafer, and you get two WSE per rack, which is 88GB of SRAM per rack. Also, 1TB of HBM is on the low-side on rack scale because just 4 Rubin chips will get you the same 1TB of HBM. A Rubin NVL144 (with 144 GPU chiplets) has 20.7TB of HBM in a single rack. We will make more detailed comparisons after the paywall.
Future SambaNova chips would surely benefit from the use of HBM4 instead of HBM2E, but the short supply and pricing is always a concern for smaller players.
You can also run different kinds of parallelism: tensor, pipeline, or expert, on the entire rack of 16 chips. When you scale up to multiple racks, the ability to slice up the data units across all 256 RDU chips makes it quite versatile as to how you can split up a large model into various pieces of hardware in the system. SambaNova’s video below explains a lot of this quite well:
Where SambaNova Fits
In terms of a deterministic compiler and SRAM capacity, SambaNova resembles Groq more than Cerebras or Rubin, but with one major difference: the ability to shape the performance based on the workload due to availability of both HBM and DDR memory tiers. This allows KV cache storage within the memory hierarchy without the immediate need for external appliances. Unlike Groq which is a one-trick pony, and Cerebras which suffers when handling large models, SambaNova is a swiss army knife due to compiler driven scheduling and high capacity memory tiers.
After the paywall, we discuss:
How SambaNova compares to Rubin
How SambaNova compares to low-latency inference hardware like Groq LPU and Cerebras WSE
The real benefits of SambaNova: 3-tier memory hierarchy, RDU’s versatility, and TCO